Сегментация изображений с U-Net на практике
Введение
В этом блог посте мы посмотрим как Unet работает, как реализовать его, и какие данные нужны для его обучения. Для этого мы будем рассматривать:
Мы не будем следовать на 100% за статьей, но мы постараемся реализовать ее суть, адаптировать под наши нужды.
Презентация проблемы
В этой задаче нам дано изображение машины и его бинарная маска(локализующая положение машины на изображении). Мы хотим создать модель, которая будет будет способна отделять изображение машины от фона с попиксельной точностью более 99%.
Для понимания того что мы хотим, gif изображение ниже:
Изображение слева - это исходное изображение, справа - маска, которая будет применяться на изображение. Мы будем использовать Unet нейронную сеть, которая будет учиться автоматически создавать маску.
Структура кода
Код был максимально упрощен для понимания как это работает. Основной код находится в этом файле main.py , разберем его построчно.
Код
Мы будем итеративно проходить через код в main.py и через статью. Не волнуйтесь о деталях, спрятанных в других файлах проекта: нужные мы продемонстрируем по мере необходимости.
Давайте
начнем
с
начала
:
def
main
():
# Hyperparameters
input_img_resize =
(572
, 572
) # The resize size of the input images of the neural net
output_img_resize =
(388
, 388
) # The resize size of the output images of the neural net
batch_size =
3
epochs =
50
threshold =
0.
5
validation_size =
0.
2
sample_size =
None
# -- Optional parameters
threads =
cpu_count()
use_cuda =
torch.cuda.is_available()
script_dir =
os.path.dirname(os.path.abspath(__file__
))
# Training callbacks
tb_viz_cb =
TensorboardVisualizerCallback(os.path.join(script_dir,"../logs/tb_viz"
))
tb_logs_cb =
TensorboardLoggerCallback(os.path.join(script_dir,"../logs/tb_logs"
))
model_saver_cb =
ModelSaverCallback(os.path.join(script_dir,"../output/models/model_"
+
helpers.get_model_timestamp()), verbose=
True
)
В первом разделе вы определяете свои гиперпараметры, их можете настроить по своему усмотрению, например в зависимости от вашей памяти GPU. Optimal parametes определяют некоторые полезные параметры и callbacks . TensorboardVisualizerCallback - это класс, который будет сохранять предсказания в tensorboard в каждую эпоху тренировочного процесса, TensorboardLoggerCallback сохранит значения функций потерь и попиксельную «точность» в tensorboard . И наконец ModelSaverCallback сохранит вашу модель после завершения обучения.
# Download the datasets
ds_fetcher =
DatasetFetcher
()
ds_fetcher.
download_dataset()
Этот раздел автоматически загружает и извлекает набор данных из Kaggle. Обратите внимание, что для успешной работы этого участка кода вам необходимо иметь учетную запись Kaggle с логином и паролем, которые должны быть помещены в переменные окружения KAGGLE_USER и KAGGLE_PASSWD перед запуском скрипта. Также требуется принять правила конкурса, перед загрузкой данных. Это можно сделать на вкладке загрузки данных конкурса
# Get the path to the files for the neural net X_train, y_train, X_valid, y_valid = ds_fetcher.get_train_files(sample_size= sample_size, validation_size= validation_size) full_x_test = ds_fetcher.get_test_files(sample_size) # Testing callbacks pred_saver_cb = PredictionsSaverCallback(os.path.join (script_dir,"../output/submit.csv.gz" ), origin_img_size, threshold)
Эта строка определяет callback функцию для теста (или предсказания). Она будет сохранять предсказания в файле gzip каждый раз, когда будет произведена новая партия предсказания. Таким образом, предсказания не будут сохранятся в памяти, так как они очень большие по размеру.
После окончания процесса предсказания вы можете отправить полученный файл submit.csv.gz из выходной папки в Kaggle.
# -- Define our neural net architecture
# The original paper has 1
input channel, in
our case
we have 3
(RGB
)
net =
unet_origin.
UNetOriginal
((3
, *img_resize))
classifier =
nn.
classifier.
CarvanaClassifier
(net, epochs)
optimizer =
optim.
SGD
(net.
parameters()
, lr=
0.01
, momentum=
0.99
)
train_ds =
TrainImageDataset
(X_train
, y_train, input_img_resize, output_img_resize, X_transform
=
aug.
augment_img)
train_loader =
DataLoader
(train_ds, batch_size,
sampler=
RandomSampler
(train_ds),
num_workers=
threads,
pin_memory=
use_cuda)
valid_ds =
TrainImageDataset
(X_valid
, y_valid, input_img_resize, output_img_resize, threshold=
threshold)
valid_loader =
DataLoader
(valid_ds, batch_size,
sampler=
SequentialSampler
(valid_ds),
num_workers=
threads,
pin_memory=
use_cuda)
print
("Training on {} samples and validating on {} samples "
.
format(len(train_loader.
dataset), len(valid_loader.
dataset)))
# Train the classifier
classifier.
train(train_loader, valid_loader, epochs, callbacks=
)
Наконец, мы делаем то же самое, что и выше, но для прогона предсказания. Мы вызываем наш pred_saver_cb.close_saver() , чтобы очистить и закрыть файл, который содержит предсказания.
Реализация архитектуры нейронной сети
Статья Unet представляет подход для сегментации медицинских изображений. Однако оказывается этот подход также можно использовать и для других задач сегментации. В том числе и для той, над которой мы сейчас будем работать.
Перед тем, как идти вперед, вы должны прочитать статью полностью хотя бы один раз. Не волнуйтесь, если вы не получили полного понимания математического аппарата, вы можете пропустить этот раздел, также как главу «Эксперименты». Наша цель заключается в получении общей картины.
Задача оригинальной статьи отличается от нашей, нам нужно будет адаптировать некоторые части соответственно нашим потребностям.
В то время, когда была написана работа, были пропущены 2 вещи, которые сейчас необходимы для ускорения сходимости нейронной сети:
Первое был изобретено всего за 3 месяца до Unet , и вероятно слишком рано, чтобы авторы Unet добавили его в свою статью.
На сегодняшний день BatchNorm используется практически везде. Вы можете избавиться от него в коде, если хотите оценить статью на 100%, но вы можете не дожить до момента, когда сеть сойдется.
Что касается графических процессоров, в статье говорится:
To minimize the overhead and make maximum use of the GPU memory, we favor large input tiles over a large batch size and hence reduce the batch to a single image
Они использовали GPU с 6 ГБ RAM, но в настоящее время у GPU больше памяти, для размещения изображений в одном batch’e. Текущий batch равный трем, работает для графического процессора в GPU с 8 гб RAM. Если у вас нет такой видеокарты, попробуйте уменьшить batch до 2 или 1.
Что касается методов augmentations (то есть искажения исходного изображения по какому либо паттерну), рассматриваемых в статье, мы будем использовать отличные от описываемых в статье, поскольку наши изображения сильно отличаются от биомедицинских изображений.
Теперь давайте начнем с самого начала, проектируя архитектуру нейронной сети:
Вот как выглядит Unet. Вы можете найти эквивалентную реализацию Pytorch в модуле nn.unet_origin.py.
Все классы в этом файле имеют как минимум 2 метода:
Давайте рассмотрим детали реализации:
Мы отслеживаем вывод последней операции ConvBnRelu в x_trace и возвращаем ее, потому что мы будем конкатенировать этот вывод с помощью стеков декодера.
Обратите внимание, что он учитывает операцию обрезки / конкатенации (окруженную оранжевым), передавая в down_tensor, который является не чем иным, как тензором x_trace, возвращаемым нашим StackEncoder .
Если вы хотите понять больше деталей каждого блока, поместите контрольную точку отладки в метод forward каждого класса, чтобы подробно просмотреть объекты. Вы также можете распечатать форму ваших тензоров вывода между слоями, выполнив печать (x.size() ).
Тренировка нейронной сети
Теперь к реальному миру. Согласно статье:
The energy function is computed by a pixel-wise soft-max over the final feature map combined with the cross-entropy loss function.
Дело в том, что в нашем случае мы хотим использовать dice coefficient как функцию потерь вместо того, что они называют «энергетической функцией», так как это показатель, используемый в соревновании Kaggle , который определяется:
X является нашим предсказанием и Y - правильно размеченной маской на текущем объекте. |X| означает мощность множества X (количество элементов в этом множестве) и ∩ для пересечения между X и Y .
Код для dice coefficient можно найти в nn.losses.SoftDiceLoss .
class SoftDiceLoss (nn.Module): def __init__(self, weight= None, size_average= True): super (SoftDiceLoss, self).__init__() def forward(self, logits, targets): smooth = 1 num = targets.size (0 ) probs = F.sigmoid(logits) m1 = probs.view(num, - 1 ) m2 = targets.view(num, - 1 ) intersection = (m1 * m2) score = 2 . * (intersection.sum(1 ) + smooth) / (m1.sum(1 ) + m2.sum(1 ) + smooth) score = 1 - score.sum() / num return scoreПричина, по которой пересечение реализуется как умножение, и мощность в виде sum() по axis 1 (сумма из трех каналов) заключается в том, что предсказания и цель являются one-hot encoded векторами.
Например, предположим, что предсказание на пикселе (0, 0) равно 0,567, а цель равна 1, получаем 0,567 * 1 = 0,567. Если цель равна 0, мы получаем 0 в этой позиции пикселя.
Мы также использовали плавный коэффициент 1 для обратного распространения. Если предсказание является жестким порогом, равным 0 и 1, трудно обратно распространять dice loss .
Затем мы сравним dice loss с кросс-энтропией, чтобы получить нашу функцию полной потери, которую вы можете найти в методе _criterion из nn.Classifier.CarvanaClassifier . Согласно оригинальной статье они также используют weight map в функции потери кросс-энтропии, чтобы придать некоторым пикселям большее ошибки во время тренировки. В нашем случае нам не нужна такая вещь, поэтому мы просто используем кросс-энтропию без какого-либо weight map.
2. Оптимизатор
Поскольку мы имеем дело не с биомедицинскими изображениями, мы будем использовать наши собственные augmentations . Код можно найти в img.augmentation.augment_img . Там мы выполняем случайное смещение, поворот, переворот и масштабирование.
Тренировка нейронной сети
Теперь можно начать обучение. По мере прохождения каждой эпохи вы сможете визуализировать, предсказания вашей модели на валидационном наборе.
Для этого вам нужно запустить Tensorboard в папке logs с помощью команды:
Tensorboard --logdir=./logs
Пример того, что вы сможете увидеть в Tensorboard после эпохи 1:
Cегментация означает выделение областей однородных по какому-либо критерию, например по яркости. Математическая формулировка задачи сегментации может иметь следующий вид .
Пусть
-функция
яркости анализируемого изображения;
X
– конечное
подмножество плоскости на котором
определена
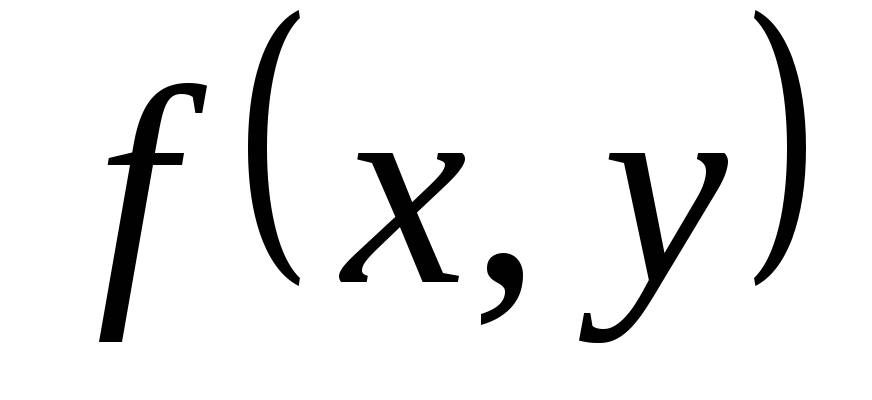 ;
; - разбиение
X
на
K
непустых
связных подмножеств
- разбиение
X
на
K
непустых
связных подмножеств
 LP
–
предикат,
определенный на множестве S
и принимающий
истинные значения тогда и только тогда,
когда любая пара точек из каждого
подмножества
LP
–
предикат,
определенный на множестве S
и принимающий
истинные значения тогда и только тогда,
когда любая пара точек из каждого
подмножества
 удовлетворяет критерию однородности.
удовлетворяет критерию однородности.
Сегментацией
изображения
 по предикату
LP
называется
разбиение
по предикату
LP
называется
разбиение

 ,
удовлетворяющее условиям:
,
удовлетворяющее условиям:
а)
 ;
;
б)
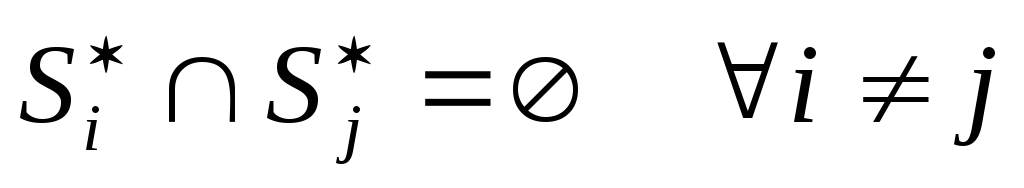 ;
;
в)
 ;
;
г) смежные области.
Условия а) и б) означают, что каждая точка изображения должна быть единственным образом отнесена к некоторой области, в) определяет тип однородности получаемых областей и, наконец, г) выражает свойство “максимальности” областей разбиения.
Предикат LP называется предикатом однородности и может быть записан в виде:
 (1)
(1)
где
 -отношение
эквивалентности;
-отношение
эквивалентности;
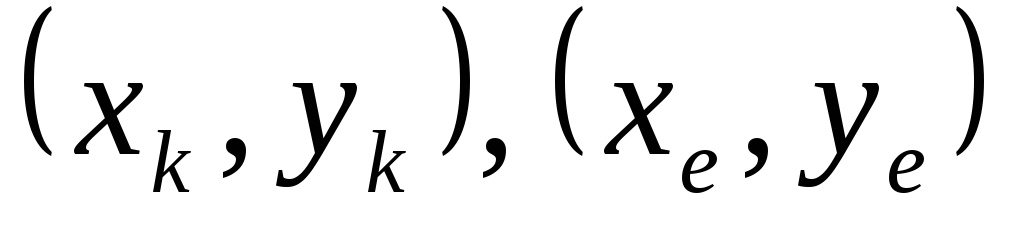 - произвольные точки из
- произвольные точки из
 .Таким образом,
сегментацию можно рассматривать как
оператор вида:
.Таким образом,
сегментацию можно рассматривать как
оператор вида:
где
 -функции,
определяющие исходное и сегментированное
изображение соответственно;
-функции,
определяющие исходное и сегментированное
изображение соответственно;
 -метка i-
й
области.
-метка i-
й
области.
Существуют
два общих подхода к решению задачи
сегментации
, которые
базируются на альтернативных
методологических концепциях. Первый
подход основан на идее “разрывности”
свойств
точек изображения при переходе от одной
области к другой. Этот подход сводит
задачу сегментации к задаче выделения
границ областей. Успешное решение
последней позволяет, вообще говоря,
идентифицировать и сами области, и их
границы. Второй подход реализует
стремление выделить точки изображения,
однородные по своим локальным свойствам,
и объединить их в область, которой позже
будет присвоено имя или смысловая метка.
В литературе первый подход называют
сегментацией
путем выделения границ областей
,
а второй – сегментацией
путем разметки точек области
.
Данное выше математическое определение
задачи позволяет характеризовать эти
подходы в терминах предиката однородности
LP
.
В первом
случае в качестве LP
должен
выступать предикат, принимающий истинные
значение на граничных точках областей
и ложные значения на внутренних точках.
Однако можно отметить существенное
ограничение этого подхода, состоящее
в том, что разбиение
 является
здесь двухэлементным множеством. В
практическом плане это означает, что
алгоритмы выделения границ не позволяют
идентифицировать разными метками разные
области.
является
здесь двухэлементным множеством. В
практическом плане это означает, что
алгоритмы выделения границ не позволяют
идентифицировать разными метками разные
области.
Для второго подхода предикат LP может иметь вид, определяемый соотношением (5.1). Указанные выше подходы порождают конкретные методы и алгоритмы решения задачи сегментации.
Пороговая обработка изображения означает преобразование его функции яркости оператором вида

где
s(x,y)
– сегментированное
изображение;
K
–
число
областей сегментации;
 - метки сегментированных областей;
- метки сегментированных областей;
 - величины порогов, упорядоченные так,
что
- величины порогов, упорядоченные так,
что
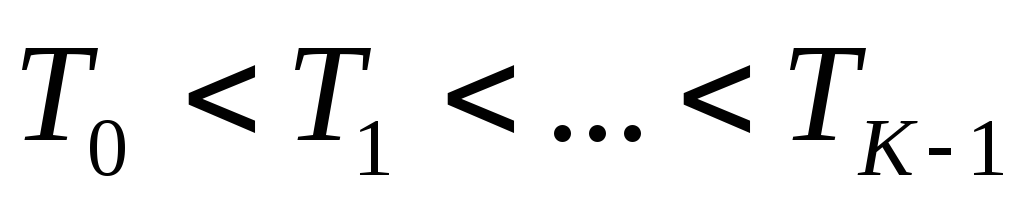 .
.
В частном случае при K= 2 пороговая обработка предусматривает использование единственного порога T . При назначении порогов применяют, как правило, гистограмму значений фунции яркости изображения.
Алгоритм сегментации на основе пороговой обработки на псевдокоде
Вход: mtrIntens – исходная матрица полутонового изображения;
l, r – пороги по гистограмме
Выход: mtrIntensNew – матрица сегментированного изображения
for i:=0 to l-1 do
for i:=l to r do
for i:=r+1 to 255 do
LUT[i]=255;
for i:=1 to 100 do
for j:=1 to 210 do
mtrIntensNew:=LUT]
Одной из основных задач обработки и анализа изображений является сегментация, т.е. разделение изображения на области, для которых выполняется определенный критерий однородности, например, выделение на изображении областей приблизительно одинаковой яркости. Понятие области изображения используется для определения связной группы элементов изображения, имеющих определенный общий признак (свойство).Операция порогового разделения, которая в результате дает бинарное изображение, называется бинаризацией. Целью операции бинаризации является радикальное уменьшение количества информации, содержащейся на изображении. В процессе бинаризации исходное полутоновое изображение, имеющее некое количество уровней яркости, преобразуется в черно-белое изображение, пиксели которого имеют только два значения – 0 и 1
Пороговая обработка изображения может проводиться разными способами.

Бинаризации с верхним порогом
Иногда можно использовать вариант первого метода, который дает негатив изображения, полученного в процессе бинаризации. Операция бинаризации с верхним порогом:
Бинаризация с двойным ограничением
Для выделения областей, в которых значения яркости пикселей может меняться в известном диапазоне, вводится бинаризация с двойным ограничением (t 1 
Так же возможны другие вариации с порогами, где пропускается только часть данных (средне полосовой фильтр).
Неполная пороговая обработка
Данное преобразование дает изображение, которое может быть проще для дальнейшего анализа, поскольку оно становится лишенным фона со всеми деталями, присутствующими на исходном изображении.
Многоуровневое пороговое преобразование
Данная операция формирует изображение, не являющееся бинарным, но состоящее из сегментов с различной яркостью.
Что касается бинаризации, то по сути все. Хотя можно добавить, что есть глобальная, которая используется для всего изображения и так же существует локальная, которая захватывает часть картинки (изображения).



Этим летом мне посчастливилось попасть на летнюю стажировку в компанию Itseez
. Мне было предложено исследовать современные методы, которые позволили бы выделить местоположения объектов на изображении. В основном такие методы опираются на сегментацию, поэтому я начала свою работу со знакомства с этой областью компьютерного зрения.
Сегментация изображения
- это разбиение изображения на множество покрывающих его областей. Сегментация применяется во многих областях, например, в производстве для индикации дефектов при сборке деталей, в медицине для первичной обработки снимков, также для составления карт местности по снимкам со спутников. Для тех, кому интересно разобраться, как работают такие алгоритмы, добро пожаловать под кат. Мы рассмотрим несколько методов из библиотеки компьютерного зрения OpenCV
.


Алгоритм работает с изображением как с функцией от двух переменных f=I(x,y) , где x,y – координаты пикселя:



Значением функции может быть интенсивность или модуль градиента. Для наибольшего контраста можно взять градиент от изображения. Если по оси OZ откладывать абсолютное значение градиента, то в местах перепада интенсивности образуются хребты, а в однородных регионах – равнины. После нахождения минимумов функции f , идет процесс заполнения “водой”, который начинается с глобального минимума. Как только уровень воды достигает значения очередного локального минимума, начинается его заполнение водой. Когда два региона начинают сливаться, строится перегородка, чтобы предотвратить объединение областей . Вода продолжит подниматься до тех пор, пока регионы не будут отделяться только искусственно построенными перегородками (рис.1).



Рис.1. Иллюстрация процесса заполнения водой
Такой алгоритм может быть полезным, если на изображении небольшое число локальных минимумов, в случае же их большого количества возникает избыточное разбиение на сегменты. Например, если непосредственно применить алгоритм к рис. 2, получим много мелких деталей рис. 3.

Рис. 2. Исходное изображение

Рис. 3. Изображение после сегментации алгоритмом WaterShed
Как справиться с мелкими деталями?
Чтобы избавиться от избытка мелких деталей, можно задать области, которые будут привязаны к ближайшим минимумам. Перегородка будет строиться только в том случае, если происходит объединение двух регионов с маркерами, в противном случае будет происходить слияние этих сегментов. Такой подход убирает эффект избыточной сегментации, но требует предварительной обработки изображения для выделения маркеров, которые можно обозначить интерактивно на изображении рис. 4, 5.

Рис. 4. Изображение с маркерами

Рис. 5. Изображение после сегментации алгоритмом WaterShed
с использованием маркеров
Если требуется действовать автоматически без вмешательства пользователя, то можно использовать, например, функцию findContours() для выделения маркеров, но тут тоже для лучшей сегментации мелкие контуры следует исключить рис. 6., например, убирая их по порогу по длине контура. Или перед выделением контуров использовать эрозию с дилатацией, чтобы убрать мелкие детали.

Рис. 6. В качестве маркеров использовались контуры, имеющие длину выше определенного порога
Mat image = imread("coins.jpg", CV_LOAD_IMAGE_COLOR);
// выделим контуры
Mat imageGray, imageBin;
cvtColor(image, imageGray, CV_BGR2GRAY);
threshold(imageGray, imageBin, 100, 255, THRESH_BINARY);
std::vector


Например, в качестве координат в пространстве признаков можно выбрать координаты пикселя (x, y) и компоненты RGB пикселя. Изобразив пиксели в пространстве признаков, можно заметить сгущения в определенных местах.

Рис. 7. (a) Пиксели в двухмерном пространстве признаков. (b) Пиксели, пришедшие в один локальный максимум, окрашены в один цвет. (с) - функция плотности, максимумы соответствуют местам наибольшей концентрации пикселей. Рисунок взят из статьи .
Чтобы легче было описывать сгущения точек, вводится функция плотности
: 
– вектор признаков i
-ого пикселя, d
- количество признаков, N
- число пикселей, h
- параметр, отвечающий за гладкость, - ядро. Максимумы функции расположены в точках сгущения пикселей изображения в пространстве признаков. Пиксели, принадлежащие одному локальному максимуму, объединяются в один сегмент. Получается, чтобы найти к какому из центров сгущения относится пиксель, надо шагать по градиенту для нахождения ближайшего локального максимума.
Оценка градиента от функции плотности
Для оценки градиента функции плотности можно использовать вектор среднего сдвига ![]()
В качестве ядра в OpenCV используется ядро Епанечникова :
- это объем d
-мерной сферы c единичным радиусом.
 означает, что сумма идет не по всем пикселям, а только по тем, которые попали в сферу радиусом h
с центром в точке, куда указывает вектор в пространстве признаков . Это вводится специально, чтобы уменьшить количество вычислений. - объем d
-мерной сферы с радиусом h, Можно отдельно задавать радиус для пространственных координат и отдельно радиус в пространстве цветов. - число пикселей, попавших в сферу. Величину
означает, что сумма идет не по всем пикселям, а только по тем, которые попали в сферу радиусом h
с центром в точке, куда указывает вектор в пространстве признаков . Это вводится специально, чтобы уменьшить количество вычислений. - объем d
-мерной сферы с радиусом h, Можно отдельно задавать радиус для пространственных координат и отдельно радиус в пространстве цветов. - число пикселей, попавших в сферу. Величину  можно рассматривать как оценку значения в области .
можно рассматривать как оценку значения в области .

Поэтому, чтобы шагать по градиенту, достаточно вычислить значение ![]() - вектора среднего сдвига. Следует помнить, что при выборе другого ядра вектор среднего сдвига будет выглядеть иначе.
- вектора среднего сдвига. Следует помнить, что при выборе другого ядра вектор среднего сдвига будет выглядеть иначе.
Если объект, который хотим выделить, состоит из областей, сильно различающихся по цвету, то MeanShift не сможет объединить эти регионы в один, и наш объект будет состоять из нескольких сегментов. Но зато хорошо справиться с однородным по цвету предметом на пестром фоне. Ещё MeanShift используют при реализации алгоритма слежения за движущимися объектами .
Пример кода для запуска алгоритма:
Mat image = imread("strawberry.jpg", CV_LOAD_IMAGE_COLOR);
Mat imageSegment;
int spatialRadius = 35;
int colorRadius = 60;
int pyramidLevels = 3;
pyrMeanShiftFiltering(image, imageSegment, spatialRadius, colorRadius, pyramidLevels);
imshow("MeanShift", imageSegment);
waitKey(0);
Результат:
Рис. 8. Исходное изображение

Рис. 9. После сегментации алгоритмом MeanShift
Такой алгоритм может быть полезен для заливки области со слабыми перепадами цвета однородным фоном. Одним из вариантов использования FloodFill
может быть выявление поврежденных краев объекта. Например, если, заливая однородные области определенным цветом, алгоритм заполнит и соседние регионы, то значит нарушена целостность границы между этими областями. Ниже на изображении можно заметить, что целостность границ заливаемых областей сохраняется:

Рис. 10, 11. Исходное изображение и результат после заливки нескольких областей
А на следующих картинках показан вариант работы FloodFill в случае повреждения одной из границ в предыдущем изображении.


Рис. 12, 13. Иллюстрация работы FloodFill
при нарушение целостности границы между заливаемыми областями
Пример кода для запуска алгоритма:
Mat image = imread("cherry.jpg", CV_LOAD_IMAGE_COLOR);
Point startPoint;
startPoint.x = image.cols / 2;
startPoint.y = image.rows / 2;
Scalar loDiff(20, 20, 255);
Scalar upDiff(5, 5, 255);
Scalar fillColor(0, 0, 255);
int neighbors = 8;
Rect domain;
int area = floodFill(image, startPoint, fillColor, &domain, loDiff, upDiff, neighbors);
rectangle(image, domain, Scalar(255, 0, 0));
imshow("floodFill segmentation", image);
waitKey(0);
В переменную area
запишется количество “залитых" пикселей.
Результат: 



Могут возникнуть сложности при сегментации, если внутри ограничивающего прямоугольника присутствуют цвета, которые встречаются в большом количестве не только в объекте, но и на фоне. В этом случае можно поставить дополнительные метки объекта (красная линия) и фона (синяя линия).



Рассмотрим идею алгоритма. За основу взят алгоритм интерактивной сегментации GraphCut, где пользователю надо поставить маркеры на фон и на объект. Изображение рассматривается как массив ![]() . Z
- значения интенсивности пикселей, N
-общее число пикселей. Для отделения объекта от фона алгоритм определяет значения элементов массива прозрачности , причем может принимать два значения, если = 0
, значит пиксель принадлежит фону, если= 1
, то объекту. Внутренний параметр содержит гистограмму распределения интенсивности переднего плана и гистограмму фона:
. Z
- значения интенсивности пикселей, N
-общее число пикселей. Для отделения объекта от фона алгоритм определяет значения элементов массива прозрачности , причем может принимать два значения, если = 0
, значит пиксель принадлежит фону, если= 1
, то объекту. Внутренний параметр содержит гистограмму распределения интенсивности переднего плана и гистограмму фона:
.
Задача сегментации - найти неизвестные . Рассматривается функция энергии:
Причем минимум энергии соответствует наилучшей сегментации.
V (a, z)
- слагаемое отвечает за связь между пикселями. Сумма идет по всем парам пикселей, которые являются соседями, dis(m,n)
- евклидово расстояние. ![]() отвечает за участие пар пикселей в сумме, если a n = a m
, то эта пара не будет учитываться.
отвечает за участие пар пикселей в сумме, если a n = a m
, то эта пара не будет учитываться. ![]() - отвечает за качество сегментации, т.е. разделение объекта от фона.
- отвечает за качество сегментации, т.е. разделение объекта от фона.
Найдя глобальный минимум функции энергии E , получим массив прозрачности . Для минимизации функции энергии, изображение описывается как граф и ищется минимальный разрез графа. В отличие от GraphCut в алгоритме GrabCut пиксели рассматриваются в RGB пространстве, поэтому для описания цветовой статистики используют смесь гауссиан (Gaussian Mixture Model - GMM). Работу алгоритма GrabCut можно посмотреть, запустив сэмпл OpenCV
Одной из основных задач обработки и анализа изображений является сегментация, т.е. разделение изображения на области, для которых выполняется определенный критерий однородности, например, выделение на изображении областей приблизительно одинаковой яркости. Понятие области изображения используется для определения связной группы элементов изображения, имеющих определенный общий признак (свойство).Операция порогового разделения, которая в результате дает бинарное изображение, называется бинаризацией. Целью операции бинаризации является радикальное уменьшение количества информации, содержащейся на изображении. В процессе бинаризации исходное полутоновое изображение, имеющее некое количество уровней яркости, преобразуется в черно-белое изображение, пиксели которого имеют только два значения – 0 и 1
Пороговая обработка изображения может проводиться разными способами.
Бинаризации с верхним порогом
Иногда можно использовать вариант первого метода, который дает негатив изображения, полученного в процессе бинаризации. Операция бинаризации с верхним порогом:
Бинаризация с двойным ограничением
Для выделения областей, в которых значения яркости пикселей может меняться в известном диапазоне, вводится бинаризация с двойным ограничением (t 1
Так же возможны другие вариации с порогами, где пропускается только часть данных (средне полосовой фильтр).
Неполная пороговая обработка
Данное преобразование дает изображение, которое может быть проще для дальнейшего анализа, поскольку оно становится лишенным фона со всеми деталями, присутствующими на исходном изображении.
Многоуровневое пороговое преобразование
Данная операция формирует изображение, не являющееся бинарным, но состоящее из сегментов с различной яркостью.
Что касается бинаризации, то по сути все. Хотя можно добавить, что есть глобальная, которая используется для всего изображения и так же существует локальная, которая захватывает часть картинки (изображения).











