Чтобы пользоваться предварительным просмотром презентаций создайте себе аккаунт (учетную запись) Google и войдите в него: https://accounts.google.com
Однозначное декодирование Прямое и обратное условие Фано Учитель информатики и ИКТ МБОУ СОШ № 7 г. Оха Сахалинской области Сергиенко Татьяна Геннадьевна
Задача 1 Пусть для кодирования фразы «Доброе утро» выбран такой код: Д О Б Р Е У Т Пробел 111 000 00 1 01 0 10 11
Коды букв «сцепляются» в единую битовую строку и передаются, например, по сети: Доброе утро→ 11100000100001110101000 В пункте назначения возникает проблема – как восстановить исходное сообщение, и возможно ли это.
11100000100001110101000 Раскодировать данное сообщение можно разными способами. В том числе предположим, что оно состоит только из букв Р – 1 и У – 0. Тогда получим РРРУУУУУРУУУУРРРУРУРУУУ, т.е. бессмысленный набор букв.
Код называется однозначно декодируемым, если любое кодовое сообщение можно расшифровать единственным способом (однозначно).
Значит, код не является однозначно декодируемым.
Задача 2 Равномерные коды. Для той же фразы используем равномерный код: Д О Б Р Е У Т Пробел 111 000 001 101 011 010 100 110
Равномерные коды неэкономичны – гораздо длиннее неравномерных. Это приводит к усложнению кодирования, но при этом они раскодируются однозначно, что, естественно, облегчает задачу.
Задача 3 Чтобы сократить длину сообщения, можно попробовать применить неравномерный код, т.е. код, в котором кодовые слова, соответствующие разным символам исходного алфавита, могут иметь разную длину, от одного до нескольких символов.
Используем следующий код: 01Эта битовая цепочка декодируется однозначно. Д О Б Р Е У Т Пробел 01 00 1011 100 1010 1101 1110 1111
Первая буква - Д (код 01), т.к. ни одно другое кодовое слово не начинается с 01. Вторая буква – О (код 00). Никакое другое слово не начинается с 00. Это же свойство, которое называется условием Фано, выполняется и для кодовых слов других букв.
УСЛОВИЕ ФАНО Никакое кодовое слово не совпадает с началом другого кодового слова. Такие коды называются префиксными (раскодируются с начала сообщения) и декодируются однозначно.
Задача 4 Рассмотрим ещё один код: Он не является префиксным, т.к. код буквы Д (10) совпадает с началом кода буквы Б (1011), У(1000) и код буквы О(00) совпадает с началом кода буквы Р (001). Д О Б Р Е У Т Пробел 10 00 1011 001 0101 1000 0111 1111
Закодируем наше сообщение: ДОБРОЕ УТРО→ 10 00 1011 001 00 0101 1111 1000 0111 001 00 Начнём раскодировать с начала. Первая – Д, или У, а дальше идут вообще разные варианты: Р или Б… Т.е. надо «заглядывать» вперёд, что очень неудобно.
Попробуем раскодировать сообщение с конца – оно однозначно декодируется! Выполняется обратное условие Фано: никакое кодовое слово не совпадает с окончанием другого кодового слова.
Коды, для которых выполняется обратное условие Фано, называются постфиксными.
Сделаем вывод: Сообщение декодируется однозначно, если для используемого кода выполняется прямое или обратное условие Фано.
Условие Фано - это достаточное, но не необходимое условие однозначной декодируемости Это значит, что: - для однозначной декодируемости достаточно выполнения хотя бы одного из двух условий - прямого или обратного. - могут существовать коды, для которых не выполняется ни прямое, ни обратное условие Фано, но тем не менее обеспечивается однозначное декодирование, т.к. иначе теряется смысл выражения.
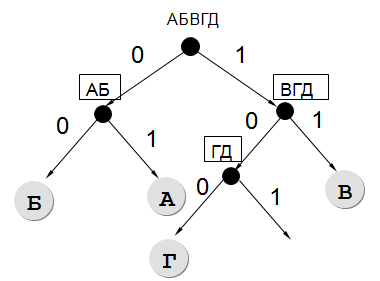
Задача 5 Для кодирования некоторой последовательности, состоящей из букв А, Б, В, Г и Д используется неравномерный двоичный код, позволяющий однозначно декодировать полученную двоичную последовательность. Вот этот код: А – 00, Б – 01, В – 100, Г – 101, Д – 110.
Можно ли сократить для одной из букв длину кодового слова так, чтобы код по-прежнему можно было декодировать однозначно? Коды остальных букв меняться не должны. Выберите правильный вариант ответа: 1) для буквы Д -11 2) это невозможно 3) для буквы Г - 10 4) для буквы Д -10
РЕШЕНИЕ: Исходный код – префиксный. Для него выполняется условие Фано – ни один из трёхбитных кодов не начинается ни с 00 (А), ни с 01 (Б). (При этом обратное условие Фано не выполняется – код А (00) совпадает с окончанием В (100), а код Б (01) совпадает с окончанием Г (101).)
Теперь проверим ответы. Сократим Д до 11. Если полученный код нарушит прямое условие Фано, то свойство однозначного декодирования будет нарушено. Но этого не произошло, нет других кодов, начинающихся с 11. Это и есть верное решение. Проверим остальные варианты.
Вариант 2 сразу не рассматриваем – ответ у нас найден. Вариант 3 нарушает прямое условие Фано – с 10 начинается код буквы В (101). Вариант 4 – так же нарушает прямое условие Фано. Т.е. ответ однозначный, других вариантов нет.
Спасибо за внимание!
Урок посвящен тому, как решать 5 задание ЕГЭ по информатике
5-я тема характеризуется, как задания базового уровня сложности, время выполнения – примерно 2 минуты, максимальный балл — 1
Пример:
Зашифруем буквы А, Б, В, Г при помощи двоичного кодирования равномерным кодом и посчитаем количество возможных сообщений:
Таким образом, мы получили равномерный код
, т.к. длина каждого кодового слова одинакова для всех кодов
(2).
Декодирование (расшифровка) - это восстановление сообщения из последовательности кодов.
Для решения задач с декодированием, необходимо знать условие Фано:
Условие Фано: ни одно кодовое слово не должно являться началом другого кодового слова (что обеспечивает однозначное декодирование сообщений с начала)
Префиксный код - это код, в котором ни одно кодовое слово не совпадает с началом другого кодового слова. Сообщения при использовании такого кода декодируются однозначно.

Однозначное декодирование обеспечивается:



ЕГЭ 5.1: Для кодирования букв О, В, Д, П, А решили использовать двоичное представление чисел 0 , 1 , 2 , 3 и 4 соответственно (с сохранением одного незначащего нуля в случае одноразрядного представления).
Закодируйте последовательность букв ВОДОПАД таким способом и результат запишите восьмеричным кодом.
Результат: 22162
Решение ЕГЭ данного задания по информатике, видео:
Рассмотрим еще разбор 5 задания ЕГЭ:
ЕГЭ 5.2: Для 5 букв латинского алфавита заданы их двоичные коды (для некоторых букв - из двух бит, для некоторых - из трех). Эти коды представлены в таблице:
| a | b | c | d | e |
|---|---|---|---|---|
| 000 | 110 | 01 | 001 | 10 |
Какой набор букв закодирован двоичной строкой 1100000100110 ?
✎ 1 вариант решения:
Результат: b a c d e.
✎ 2 вариант решения:
 110
000 01
001 10
110
000 01
001 10
Результат: b a c d e.
Кроме того, вы можете посмотреть видео решения этого задания ЕГЭ по информатике:
Решим следующее 5 задание:
ЕГЭ 5.3:
Для передачи чисел по каналу с помехами используется код проверки четности. Каждая его цифра записывается в двоичном представлении, с добавлением ведущих нулей до длины 4 , и к получившейся последовательности дописывается сумма её элементов по модулю 2 (например, если передаём 23 , то получим последовательность 0010100110).
Определите, какое число передавалось по каналу в виде 01100010100100100110 .
Ответ: 6 5 4 3
Вы можете посмотреть видео решения этого задания ЕГЭ по информатике:
ЕГЭ 5.4:
Для кодирования некоторой последовательности, состоящей из букв К, Л, М, Н решили использовать неравномерный двоичный код, удовлетворяющий условию Фано. Для буквы Н использовали кодовое слово 0 , для буквы К - кодовое слово 10 .
Какова наименьшая возможная суммарная длина всех четырёх кодовых слов?
✎ 1 вариант решения основан на логических умозаключениях:
✎ 2 вариант решения :
 (Н) -> 0 -> 1 символ
(К) -> 10 -> 2 символа
(Л) -> 110 -> 3 символа
(М) -> 111 -> 3 символа
(Н) -> 0 -> 1 символ
(К) -> 10 -> 2 символа
(Л) -> 110 -> 3 символа
(М) -> 111 -> 3 символа
Ответ: 9
ЕГЭ по информатике 5 задание 2017 ФИПИ вариант 2 (под редакцией Крылова С.С., Чуркиной Т.Е.):
По каналу связи передаются сообщения, содержащие только 4 буквы: А, Б, В, Г; для передачи используется двоичный код, допускающий однозначное декодирование. Для букв А, Б, В используются такие кодовые слова: А: 101010 , Б: 011011 , В: 01000 .
Г, при котором код будет допускать однозначное декодирование. наименьшим числовым значением.
Результат: 00
ЕГЭ по информатике 5 задание 2017 ФИПИ вариант 16 (под редакцией Крылова С.С., Чуркиной Т.Е.):
Для кодирования некоторой последовательности, состоящей из букв А, Б, В, Г и Д, решили использовать неравномерный двоичный код, позволяющий однозначно декодировать двоичную последовательность, появляющуюся на приемной стороне канала связи. Использовали код: А — 01 , Б — 00 , В — 11 , Г — 100 .
Укажите, каким кодовым словом должна быть закодирована буква Д.
Длина
этого кодового слова должна быть наименьшей
из всех возможных. Код должен удовлетворять свойству однозначного декодирования. Если таких кодов несколько, укажите код с наименьшим числовым значением.
Результат: 101
Подробней разбор урока можно посмотреть на видео ЕГЭ по информатике 2017:
ЕГЭ по информатике 5 задание 2017 ФИПИ вариант 17 (Крылов С.С., Чуркина Т.Е.):
Для кодирования некоторой последовательности, состоящей из букв А, Б, В, Г, Д и Е, решили использовать неравномерный двоичный код, позволяющий однозначно декодировать двоичную последовательность, появляющуюся на приемной стороне канала связи. Использовали код: А — 0 , Б — 111 , В — 11001 , Г — 11000 , Д — 10 .
Укажите, каким кодовым словом должна быть закодирована буква Е. Длина этого кодового слова должна быть наименьшей из всех возможных. Код должен удовлетворять свойству однозначного декодирования. Если таких кодов несколько, укажите код с наименьшим числовым значением.
 1 - не подходит (все буквы кроме А начинаются с 1)
10 - не подходит (соответствует коду Д)
11 - не подходит (начало кодов Б, В и Г)
100 - не подходит (код Д - 10 - является началом данного кода)
101 - не подходит (код Д - 10 - является началом данного кода)
110 - не подходит (начало кода В и Г)
111 - не подходит (соответствует коду Б)
1000 - не подходит (код Д - 10 - является началом данного кода)
1001 - не подходит (код Д - 10 - является началом данного кода)
1010 - не подходит (код Д - 10 - является началом данного кода)
1011 - не подходит (код Д - 10 - является началом данного кода)
1100 - не подходит (начало кода В и Г)
1101 - подходит
1 - не подходит (все буквы кроме А начинаются с 1)
10 - не подходит (соответствует коду Д)
11 - не подходит (начало кодов Б, В и Г)
100 - не подходит (код Д - 10 - является началом данного кода)
101 - не подходит (код Д - 10 - является началом данного кода)
110 - не подходит (начало кода В и Г)
111 - не подходит (соответствует коду Б)
1000 - не подходит (код Д - 10 - является началом данного кода)
1001 - не подходит (код Д - 10 - является началом данного кода)
1010 - не подходит (код Д - 10 - является началом данного кода)
1011 - не подходит (код Д - 10 - является началом данного кода)
1100 - не подходит (начало кода В и Г)
1101 - подходит
Результат: 1101
Более подробное решение данного задания представлено в видеоуроке:
5 задание. Демоверсия ЕГЭ 2018 информатика (ФИПИ):
По каналу связи передаются шифрованные сообщения, содержащие только десять букв: А, Б, Е, И, К, Л, Р, С, Т, У. Для передачи используется неравномерный двоичный код. Для девяти букв используются кодовые слова.
Укажите кратчайшее кодовое слово для буквы Б
, при котором код будет удовлетворять условию Фано.
Если таких кодов несколько, укажите код с наименьшим
числовым значением.

Результат: 1100
Подробное решение данного 5 задания из демоверсии ЕГЭ 2018 года смотрите на видео:
Задание 5_9. Типовые экзаменационные варианты 2017. Вариант 4 (Крылов С.С., Чуркина Т.Е.):
По каналу связи передаются шифрованные сообщения, содержащие только четыре букв: А, Б, В, Г; для передачи используется двоичный код, допускающий однозначное декодирование. Для букв А , Б , В используются кодовые слова:
А: 00011 Б: 111 В: 1010
Укажите кратчайшее кодовое слово для буквы Г
, при котором код будет допускать однозначное декодирование.
Если таких кодов несколько, укажите код с наименьшим
числовым значением.

Результат: 00
Задание 5_10. Тренировочный вариант №3 от 01.10.2018 (ФИПИ):
По каналу связи передаются сообщения, содержащие только буквы: А, Е, Д, К, М, Р ; для передачи используется двоичный код, удовлетворяющий условию Фано. Известно, что используются следующие коды:
Е – 000 Д – 10 К – 111
Укажите наименьшую возможную длину закодированного сообщения ДЕДМАКАР
.
В ответе напишите число – количество бит.
 Д Е Д М А К А Р
10 000 10 001 01 111 01 110
Д Е Д М А К А Р
10 000 10 001 01 111 01 110
Результат: 20
Смотрите виде решения задания:
Рассмотрим другую кодовую таблицу: А Б В Г Д 000 01 10 011 100 Здесь условие Фано не выполняется, поскольку код буквы Б (01) является началом кода буквы Г (011), а код буквы Д (100) начинается с кода буквы В (10). Тем не менее, можно заметить, что выполнено «обратное» условие Фано: ни один код не является окончанием другого кода (такой код называют постфиксным). Поэтому закодированное сообщение можно однозначно декодировать с конца. Например, рассмотрим цепочку 011000110110. Последней буквой в этом сообщении может быть только В (код 10): В 0110001101 10 Вторая буква с конца – Б (код 01): Б В 01100011 01 10 и так далее: Б Д Г Б В 01 100 011 01 10.
Слайд 26 из презентации «Методы кодирования информации» . Размер архива с презентацией 734 КБ.«Двоичное кодирование» - Цифры. Двоичное кодирование текстовой информации. Таблица кодировки. Информационный объем текста. Двоичное кодирование в компьютере. Кодирование текстовой информации. Таблица расширенного кода. Символ. Уникальный двоичный код. Буква латинского алфавита. Использование двоичной системы. Компьютеры.
«Кодирование информации в двоичном коде» - Определение. Системы счисления. Двоичная система счисления. Кодирование. Кодирование информации. Приведите примеры кодирования. Десятичная система счисления. Значение цифры. Значение цифры зависит от ее положения. Алфавит. Языки. Римская непозиционная система. Двоичное кодирование. Что здесь зашифровано.
«Способы кодирования» - Номер столбца. Буква исходного текста. Кодирование информации. Способы кодирования информации. Декодируйте информацию. Передаваемая информация. В мире кодов. Автоматическое кодирование. Метод координат. Достоинства и недостатки. Разнообразие кодов. Мальчик. Как можно назвать записную книжку с точки зрения хранения информации. Закодированный текст. Носитель информации. Ключевые слова. Разгадайте ребус.
«Способы кодирования информации» - В памяти компьютера информация представлена в двоичном коде. Кодирование и декодирование. Можно закодировать информацию. Способы кодирования информации. Составим простейшую кодовую таблицу. Чтобы узнать зашифрованное слово, возьмите только первые слоги. Что прочитал Лом на флагах встречной шхуны. Придумайте собственный способ кодирования букв русского алфавита. Задания. Зашифрованная информация. Луи Брайль придумал специальный способ представления информации.
«Методы кодирования информации» - Двоичное кодирование в компьютере. Количество информации. Оптический телеграф Шаппа. Условие Фано. Какой код использовать. Получено сообщение. «Да» или «Нет». Первый телеграф. Способы кодирования информации. Запись информации. Почему двоичное кодирование. Сигнальные флаги. Кодирование. Кодирование и декодирование. Кодирование информации. Выбор способа кодирования. Виды информации. Сколько вариантов.
На тестах для подготовки к ЕГЭ по информатике встречаются задачи на применение условия Фано. Материала в учебниках не нашел. Заходим в Википедию.
Условие Фано (англ. Fano condition, в честь Роберта Фано) - в теории кодирования необходимое условие построения самотерминирующегося кода (в другой терминологии, префиксного кода). Обычная формулировка этого условия выглядит так:
Никакое кодовое слово не может быть началом другого кодового слова.
Более «математическая» формулировка:
Если в код входит слово a, то для любой непустой строки b слова ab в коде не существует.
Алгоритм Шеннона - Фано - один из первых алгоритмов сжатия, который впервые сформулировали американские учёные Шеннон и Роберт Фано. Данный метод сжатия имеет большое сходство с алгоритмом Хаффмана, который появился на несколько лет позже. Алгоритм использует коды переменной длины: часто встречающийся символ кодируется кодом меньшей длины, редко встречающийся - кодом большей длины. Коды Шеннона - Фано префиксные, то есть никакое кодовое слово не является префиксом любого другого. Это свойство позволяет однозначно декодировать любую последовательность кодовых слов.
Основные сведения
Кодирование Шеннона- Фано(англ. coding) - алгоритм префиксного неоднородного кодирования. Относится к вероятностным методам сжатия (точнее, методам контекстного моделирования нулевого порядка). Подобно алгоритму Хаффмана, алгоритм Шеннона - Фано использует избыточность сообщения, заключённую в неоднородном распределении частот символов его (первичного) алфавита, то есть заменяет коды более частых символов короткими двоичными последовательностями, а коды более редких символов - более длинными двоичными последовательностями.
Алгоритм был независимо друг от друга разработан Шенноном (публикация «Математическая теория связи», 1948 год) и, позже, Фано (опубликовано как технический отчёт).
1. Основные понятия
Закодировать текст – значит сопоставить ему другой текст. Кодирование применяется при передаче данных – для того, чтобы зашифровать текст от посторонних, чтобы сделать передачу данных более надежной, потому что канал передачи данных может передавать только ограниченный набор символов (например, - только два символа, 0 и 1) и по другим причинам.
При кодировании заранее определяют алфавит, в котором записаны исходные тексты (исходный алфавит) и алфавит, в котором записаны закодированные тексты (коды), этот алфавит называется кодовым алфавитом. В качестве кодового алфавита часто используют двоичный алфавит, состоящий из двух символов (битов) 0 и 1. Слова в двоичном алфавите иногда называют битовыми последовательностями.
2. Побуквенное кодирование
Наиболее простой способ кодирования – побуквенный. При побуквенном кодировании каждому символу из исходного алфавита сопоставляется кодовое слово – слово в кодовом алфавите. Иногда вместо «кодовое слово буквы» говорят просто «код буквы». При побуквенном кодировании текста коды всех символов записываются подряд, без разделителей.
Пример 1. Исходный алфавит – алфавит русских букв, строчные и прописные буквы не различаются. Размер алфавита – 33 символа.
Кодовый алфавит – алфавит десятичных цифр. Размер алфавита - 10 символов.
Применяется побуквенное кодирование по следующему правилу: буква кодируется ее номером в алфавите: код буквы А – 1; буквы Я – 33 и т.д.
Тогда код слова АББА – это 1221.
Внимание: Последовательность 1221 может означать не только АББА, но и КУ (К – 12-я буква в алфавите, а У – 21-я буква). Про такой код говорят, что он НЕ допускает однозначного декодирования
Пример 2. Исходный и кодовый алфавиты – те же, что в примере 1. Каждая буква также кодируется своим номером в алфавите, НО номер всегда записывается двумя цифрами: к записи однозначных чисел слева добавляется 0. Например, код А – 01, код Б – 02 и т.д.
В этом случае кодом текста АББА будет 01020201. И расшифровать этот код можно только одним способом. Для расшифровки достаточно разбить кодовый текст 01020201 на двойки: 01 02 02 01 и для каждой двойки определить соответствующую ей букву.
Такой способ кодирования называется равномерным. Равномерное кодирование всегда допускает однозначное декодирование.
Далее рассматривается только побуквенное кодирование
3. Неравномерное кодирование
Равномерное кодирование удобно для декодирования. Однако часто применяют и неравномерные коды, т.е. коды с различной длиной кодовых слов. Это полезно, когда в исходном тексте разные буквы встречаются с разной частотой. Тогда часто встречающиеся символы стоит кодировать более короткими словами, а редкие – более длинными. Из примера 1 видно, что (в отличие от равномерных кодов!) не все неравномерные коды допускают однозначное декодирование.
Есть простое условие, при выполнении которого неравномерный код допускает однозначное декодирование.
Код называется префиксным, если в нем нет ни одного кодового слова, которое было бы началом (по-научному, - префиксом) другого кодового слова.
Но я хочу продемонстрировать как можно автоматизировать данный процесс.
Видеоролик выложу в интернет
Приведу пример из подготовки к ЕГЭ по информатике (фирма 1С - материалы Центра Сертифицированного Обучения):
Для кодирования некоторой последовательности, состоящей из букв С, Т, Р, О, К и А, используется неравномерный двоичный код, удовлетворяющий условию Фано, и следовательно, позволяющий однозначно декодировать полученную двоичную последовательность. Вот этот код: С - 000, Т - 001, Р - 010, О - 100, К - 011, А - 11. Можно ли сократить для одной из букв длину кодового слова так, чтобы код по прежнему удовлетворял условию Фано? Коды остальных букв меняться не должны.
Выберите правильный вариант ответа.
Варианты ответов:
1) для буквы Р - 01
2) для буквы О - 10
3) для буквы А - 1
4) это невозможно
Правильный вариант - 2
Решение:
Вариант 1) не подходит - условие Фано будет нарушено для букв Р и К
Вариант 2) подходит - слово 10 не является началом кодовых слов для других букв
Вариант 3) не подходит - условие Фано будет нарушено для букв А и О
Вариант 4) не подходит - см. вариант 2)
Теперь посмотрим, что выдаст программа для автоматизированного решения подобных задач и контроля знаний.
В задании не задана частотность или вероятность появления букв, поэтому в программе примем ее равной 0,01 для всех букв.
Вероятности:
0.01, 0.01, 0.01, 0.01, 0.01, 0.01
Значения:
C, T, P, O, K, A
Результат:
C 000
T 001
P 01
O 100
K 101
A 11
Из решения видно, вариантов решения может быть несколько, но все они отвечают условию Фано.
Полагаю, что подобные программы будут полезны для контроля знаний, а включение подобной функции в язык программирования усилит возможности языка, поэтому включаю данную функцию в язык SmartMath. Программа сама определяет количество символов для анализа, сортирует их в зависимости от частотности и присваивает коды согласно условия Фано. Преимущество автоматизации в создании кода при выполнении условия Фано в том, что можно быстро создавать решения для любой последовательности.
Смотрите ссылку.
Естественно возникает вопрос: существуют ли неравномерные коды, для которых декодирование всегда однозначно? Да, существуют.
Роберт Фано сформулировал следующее достаточное условие того, что код имеет однозначное декодирование: никакое кодовое слово не является началом другого кодового слова. Если это условие выполнено, то никаких проблем с декодированием не будет.
Пусть A 1 , A 2 и A 3 - слова над некоторым алфавитом такие, что A 1 =A 2 A 3 , то есть A 1 получается из A 2 простым приписыванием к нему слова A 3 (слова A 2 или A 3 могут быть односимвольными). Назовем слово A 2 , которое является начальной частью слова A 1 , префиксом слова A 1 . Например, для слова 11101101 префиксами будут слова 1110110 , 111011 , 11101 , 1110 , 111 , 11 , 1 .
Тогда условие Фано для кодов, можно сформулировать так:
Никакое кодовое слово не является префиксом другого кодового слова .
Коды, удовлетворяющие условию Фано, называются префиксными . Итак, если код префиксный, он допускает однозначное декодирование.
Например, код, состоящий из кодовых слов {0, 10, 11} , является префиксным, и следующую кодовую последовательность 01001101110 можно разбить на кодовые слова единственным образом: 0 10 0 11 0 11 10 .
А код, состоящий из кодовых слов {0, 10, 11, 100} , префиксным не является и он не допускает однозначного декодирования. Действительно, ту же самую последовательность можно разбить на кодовые слова разными способами: 0 10 0 11 0 11 10 или 0 100 11 0 11 10 .
Важно отметить, что условие Фано является только достаточным условием однозначного декодирования для кодов, но не является необходимым условием.
Например, простой код, состоящий всего из двух кодовых слов {1, 10} , очевидно не является префиксным, но он дает однозначное декодирование любой кодовой последовательности, полученной при кодировании этим кодом. Действительно, в такой последовательности не может стоять рядом два нуля. А тогда каждый ноль со стоящей перед ней единицей заменяем на прообраз второго кодового слова, а все оставшиеся единицы - на прообраз первого слова, это и будет однозначным декодированием.
Существуют и другие, менее простые коды, обладающие тем же свойством. Например, код {01,10,011} также не является префиксным, но обладает однозначным декодированием (попробуйте доказать это самостоятельно).
Как же все-таки определить является ли код однозначно декодируемым, если для него не выполняется условие Фано? Можно использовать следующий метод.
Пусть слово A 2 является префиксом слова A 1 . Тогда A 1 =A 2 A 3 , где A 3 некоторое слово, конечная часть слова A 1 . Назовем A 3 суффиксом пары слов A 1 и A 2 , одно из которых является префиксом другого, а саму пару A 1 и A 2 назовем префиксной .
Рассмотрим в заданном коде все префиксные пары кодовых слов и построим по ним множество всех суффиксов. Далее рассмотрим все пары префиксных слов, из которых одно является кодовым, а другое – суффиксом, и для них построим суффиксы, расширяя множество суффиксов. Продолжим этот процесс до тех пор пока не перестанут появляться новые суффиксы. Код является однозначно декодируемым тогда и только тогда, когда никакой суффикс не совпадает ни с каким кодовым словом.
Например, для кода {01,10,011} множеством суффиксов будет {1,0,11} . Ни один суффикс здесь не совпадает ни с одним кодовым словом, поэтому, можно утверждать, что этот код является однозначно декодируемым.
Задача 1. Определить обладают ли свойством однозначной декодируемости следующие коды: а) {110, 11, 100, 00, 10} б) {100, 001, 101, 1101, 11011} .
Декодирование последовательностей, полученных кодами, не являющимися префиксными, требует более сложного анализа, чем для префиксных кодов. Префиксные коды иногда называют мгновенными (мгновенно декодируемыми), так как для них при чтении кодовой последовательности конец кодового слова распознается сразу по достижении конечного символа слова. В этом состоит преимущество префиксных кодов.











