Добрый день, мои уважаемые читатели. Сегодня мы коснемся чрезвычайно интересной и важной темы – информационно поисковые системы. Умение правильно работать с ними, знание основных понятий и принципов работы смогут помочь начинающим пользователям научиться быстро и оперативно искать различную информацию в сети, получать нужные данные и быстро развивать свой интернет бизнес.
В данной статье я расскажу об истории создания систем поиска, принципах их работе и структуре. Помимо этого, остановлюсь на очень важных фишках, которые необходимо обязательно знать при работе с ИПС.
Итак, давайте более подробно изучим, что такое ИПС, какие компоненты входят в их состав.
Данное понятие возникло еще в конце 80 – х, начале 90 – х годов прошлого века. Именно тогда и возникли их первые прототипы, как в России, так и за рубежом. Согласно определению – это система, которая позволяет искать, обрабатывать, отбирать требуемые данные запроса в своей особой базе, где находятся описания различных источников информации, а также правила пользования ими.
Основной ее задачей является поиск нужной пользователю информации. Для того, чтобы он был более эффективным, используется понятие релевантности, то есть то, насколько сами результаты поиска точно подходят тому или иному запросу.
К основным типам ИПС относятся следующие понятия:
Индексация каталога может производиться, как вручную, так и автоматически с обновлением индекса. В свою очередь сам результат работы системы включает в себя особый список. В него входят гиперссылка на требуемые ресурсы и описание того или иного документа в интернете.
Из наиболее популярных каталогов можно выделить: Yahoo , Magellan (зарубежные) и Weblist , Улитка и @ Rus из отечественных.

К наиболее распространенным зарубежным ИПС относят – Google, Altavista, Excite. Русские – «Яндекс» и «Рамблер».
Самые первые ИПС появились в середине 90 – х годов 20 века. Они весьма напоминали обычные указатели, которые находятся в любых книгах, некие справочники. В их базе данных содержались специальные ключевики (слова), которые различными способами собирались с многочисленных сайтов. Так, как интернет – технологии были не совершенными, то и сам поиск выполнялся только по ключевым словам.
Значительно позднее был разработан специальный полнотекстовый поиск, облегчающий нахождение необходимой пользователю информации. Система производила фиксацию ключевых слов. Благодаря ей, пользователи могли производить нужные запросы по тем или иным словам и различным словосочетаниям.

Одной из первых, была «Wandex». Ее разработкой занимался очень известный программист Мэтью Греэм в 1993 году. Также, в этом же году возникла и новая «поисковка» «Aliweb» (кстати, и по сей день успешно работает). Однако все они имели достаточно сложную структуру и не обладали современными технологиями.
Одной из наиболее удачных явилась «WebCrawler», которая впервые была запущена в 1994 году. Отличительной особенностью и главным преимуществом, выгодно выделяющим ее среди других систем поиска, явилось то, что она могла находить любые ключевики на той или иной странице. После этого, это стало своего рода эталоном и для всех остальным ИПС, которые разрабатывались позднее.
Значительно позже возникли и другие поисковики, которые иногда конкурировали между собой. Это были – «Excite», «AltaVista», «InfoSeek», «Inktomi» и многие другие. Начиная с 96 года, российские пользователи сети начали работать с «Рамблером» и «Апортом». Но, настоящим триумфом для российского интернета, стал созданный в 1997 году «Яндекс».
Этот российский аналог «Google» стал настоящей гордостью российских программистов. Сегодня, он уверенно теснит конкурента в рунете и также является одним из лидеров по поисковым запросам среди ИПС в России.
На сегодняшний день, имеются многочисленные специальные «поисковики», которые созданы для решения определенных задач. Так, например, информационно – поисковая система «Патрон», разработана для того, чтобы хранить и искать данные по патронам для различного оружия и сейчас применяется, как в органах Министерства Внутренних Дел и спецслужб, так и для охотников – профессионалов и любителей.
Имеются и другие, разработанные для нотариусов, врачей, инженеров, военных, автолюбителей и т д

Работа информационно – поисковой системы является очень сложной. Однако при желании можно разобраться в ее структуре. Первое, что необходимо отметить, что существует особая программа – она называется поисковым роботом (пауком). Данная программа систематически мониторит различные страницы и индексирует их.
Веб сервер создает запрос пользователя на получение той или иной информации, а затем предоставляет данный запрос машине поиска. Поисковик исследует требуемую базу данных, потом составляет полный список страниц, а затем передает веб-серверу. Он в свою очередь окончательно формирует все результаты запроса в «читаемый» вид, затем передает их на «комп» пользователя.
ИПС предназначена для следующих целей:
Существуют несколько основных типов ИПС:

На первом месте, без всякого сомнения, находиться неотъемлемый лидер – «Google». На сегодняшний день, к нему адресуется около 80 процентов различных мировых запросов по самым различным сферам. Что касается второго места, то его, также заслуженно, занимает американский «eBay».
На третьем месте, наш, отечественный, российский «Яндекс». На четвертом – «Yahoo» и на пятом – MSN. Еще одним отечественным браузером, но занимающим только 10 место в рейтинге Европы – это российский «Rambler».
Этот поисковик знают огромное количество пользователей. На сегодняшний день это первая по популярности система в мире! Ежемесячно она обрабатывает более 41 млрд запросов и проводит индексацию 25 миллиардов страниц.
Что касается истории создания компании «Google», то еще в 1996 году, пара студентов университета Стэнфорда – Ларри Пейдж и Сергей Брин разработали браузер, созданный на новых методах поиска. Назвали они ее просто и лаконично, как собственно и дизайн поисковой системы «Google». Собственно название google – это искаженный googol (число десять в сотой степени).

В основе нее специальный поисковый робот, который называется «Googlebot». Он производит сканирование страниц и их индексацию. В качестве алгоритма авторитетности, эта ПС . Собственно именно он обеспечивает то, как будут выдаваться страницы посетителю в поисковых результатах.
Одним из первых, эта фирма разработала и на различных языках, который значительно облегчает введение данных в систему. Ну, и наконец, именно и послужил основой для слова «гуглить», которое все чаще встречается в сленге молодых тинейджеров.
«Yahoo » – вторая по популярности в США. Ее организовали в 1994 году два аспиранта Стэнфорда – Дэвид Фило и Джерри Янг. В конце 90 –х ими был приобретен портал RocketMail и на основе него создан бесплатный почтовый сервер «Yahoo». Сегодня на ее серверах можно хранить любое количество писем. В 2010 году появляется и русскоязычный ресурс почты – Yahoo! Почта.
Яндекс
Одним из лучших российских поисковиков, вне всякого сомнения, является «Яндекс». На сегодняшний день он стоит на четвертом месте по общему количеству запросов. В то же самое время, по популярности «Яндекс» занимает сегодня первое место в Российской Федерации. Общее количество произведенных запросов превышает 250 миллионов каждый день
Он был представлен в сентябре 1997 года, а уже в мае 2011, произведя размещение своих акций на IPO, эта фирма смогла заработать наибольшее количество акций среди других интернет – компаний.

Сегодня, «Yandex» имеет 50 сервисов, из которых некоторые уникальные – Яндекс.Поиск, Яндекс.Карты, Яндекс.Маркет. Помимо этого, российских пользователей очень интересуют такие сервисы, как «Поиск по блогам», «Яндекс Пробки». Основные запросы для пользователей в основном из следующих стран ближнего зарубежья: Россия, Белоруссия, Турция и Казахстан.
Исторически фирму основал бизнесмен – программист Аркадий Волож в 1989 году. Само название компании было придумано Ильей Сегаловичем, директором «Яндекса». Благодаря сотрудничеству с институтом проблем передачи информации был создан справочный словарь с поиском.
В отличие от других браузеров, учитывает и морфологию русского языка. Таким образом, сама система предназначена именно для работы в русскоязычном сегменте интернета.
Начиная с 2010 года, помимо браузера «Yandex.ru» появился еще один поисковик «Yandex.com». Данный интернет – ресурс используется для поиска по зарубежным порталам.
Поисковая система « Ebay »
Ebay представляет собой интернет – компанию из США, которая специализируется на проведении интернет – аукционов. Она производит управление портала eBay.com, а также версиями в других странах мира. Помимо этого, в собственности фирмы есть еще одна eBay Enterprise.

Основателем фирмы является американский программист Пьер Омидьяр, который в середине 90 – х годов разработал интернет – аукцион для своего личного портала. В то же время, eBay – это своего рода посредник при купле продаже. Чтобы использовать его продавцы вносят определенный взнос, а покупатели получают возможность бесплатного использования сайта.
Общие принципы его работы следующие:
Уже в 1995 году на тысячах онлайн аукционов продавались миллионы различных предметов. Сегодня, это мощная платформа для купли продажи, как физлицами, так и юрлицами.
С 2010 года возникла и русскоязычная версия популярного ресурса и стала называться «Международный торговый центр eBay». Оплата на аукционе производится через платежную систему «PayPal».
Для того, чтобы продать предметы на данном портале необходимо написать сколько он стоит, его стартовая цена, когда начнутся торги, а также сколько будут длиться торги. Как и в обычном аукционе, выбранный товар получает заплативший самую высокую цену.
Из плюсов подобного аукциона стоит отметить то, что продавец и покупатель могут находиться в любом месте земного шара, а наличие локальных филиалов и временных рамок предоставляют возможность участвовать в аукционах огромному количеству продавцов и покупателей.

Данная поисковая система является ведущим интернет – браузером, разработанным компанией «Microsoft». Он появился одновременно с выпуском первой операционной системы Windows 95. Далее этим названием стал пользоваться и сервис электронной почты Hotmail, а также различные веб-узлы Майкрософт. В начале 2002 года он являлся одним из самых крупных интернет – провайдеров в США и имел 9 миллионов подписчиков.
Поисковая система Rambler
Вторым крупным российским поисковиком, является интернет – портал «Rambler». По своей сути, вместе с «Яндекс» он является родоначальником рунета, а также главным игроком на рынке медиа услуг.
Основателем его является Сергей Лысаков, который в 1994 году разработала поисковую систему, а в 1996 году был зарегистрирован и домен www.rambler.ru. Начиная с 2012 года, «Рамблер» стал работать, как новостной портал.
Сегодня он имеет 11 место по популярности среди других сайтов РФ. Также, был разработан и специальный классификатор Rambler Top-100. По своей сути он был первый и в России. Сегодня – это удобный каталог объектов недвижимости «Rambler – недвижимость».
Поисковик mail

Одной из самых крупных почтовых служб явилась, созданная в 1998 году, Mail.ru. Сегодня она представляет собой службу электронной почты, каталог интернет – ресурсов и информационные разделы. Помимо очень удобной почты, она имеет ряд специальных проектов, которые весьма популярны и нужны подписчикам: «Авто Mail.ru», Афиша «Mail.ru», «Дети mail.ru», «Здоровье mail.ru», «Леди mail.ru», «Новости mail.ru» и «Недвижимость mail.ru».
Для любителей спорта и Hi-Tech есть соответствующие рубрики.
На этом я завершаю свой материал. Если вам нравилось, то, пожалуйста, подписывайтесь на мой блог и приглашайте своих родных, друзей и знакомых.
(Пока оценок нет)
Прочитано: 469 раз
Как только посылка поступит на один из наших складов за рубежом или в России, вы получите оповещение по электронной почте. В дальнейшем Вы сможете отследить Вашу посылку на нашем сайте в разделе «Отслеживание», для этого необходимо ввести свой tracking-number.
Пожалуйста, убедитесь что Вы верно указали свой почтовый адрес в профиле IPS, и что Ваш электронный почтовый ящик не переполнен.
Если ваш продавец (интернет-магазин) сообщил Вам, что Ваша посылка прибыла в один из наших офисов, но вы все еще не можете отследить ее, пожалуйста, свяжитесь с нами, по возможности, предоставив полную информацию о вашей посылке (название магазина, отправителя и адрес отправления, идентификационный номер, дату отправления и т.д.).
Доставка посылки из-за границы. Как это работает?
Всем нашим клиентам (будь это постоянный клиент или клиент, желающий получить посылку единоразово) мы предоставляем почтовые адреса в трех городах мира – Лондоне, Нью-Йорке, Ганновере. На любой из них Ваш респондент (интернет-магазин, друг, родственник, коллега и т.п.) может выслать Вам посылку и через – 7-10 рабочих дней после того, как она поступит на один из этих адресов, Вы получите ее в Москве.
Как мне получить адреса?
Есть два варианта:
Вам нужно подъехать с паспортом в офис IPS. Здесь сделают ксерокопию Вашего паспорта, запишут Ваши контактные телефоны и выдадут нужный Вам адрес (в Лондоне, в Нью-Йорке или в Ганновере).
Вам имеет смысл заключить договор на постоянное обслуживание. Для этого нужно абонировать почтовый ящик и регулярно вносить абонентский платеж. Минимальный размер месячной абонентской платы – 755,2руб (с учетом НДС 18%). (Есть и другие размеры абонентской платы, они зависят от набора дополнительный бесплатных услуг, уже включенных в абонентское обслуживание). В этом случае Вы получаете все три адреса и можете пользоваться ими по своему усмотрению.
Для получения адреса - можно мне к Вам не приезжать, а отправить копию паспорта по e-mail?
Можно, но тогда нужна предоплата.
В двух вышеуказанных случаях (см. вопрос 2) мы обслуживаем клиентов в режиме наложенного платежа - мы привозим (т.е. сначала оказываем услугу), а потом только получаем оплату от клиента. Поэтому для нас важно удостовериться, что наш клиент –реальное лицо.
Если Вы хотите нам отправить копию паспорта электронно, то для дальнейшего обслуживания важна предоплата от Вас в размере не менее 4000,0 руб. Если после оказания и оплаты услуги доставки у Вас остается сумма – по первому Вашему требованию эта сумма будет Вам возвращена на те реквизиты, с которых она была отправлена Вами нам. Либо в дальнейшем вы сможете использовать ее для оплаты услуг в нашей компании.
Почему выгодно абонировать почтовый ящик?
Клиент, который абонирует почтовый ящик, становится нашим постоянным клиентом.
Постоянные клиенты имеют следующие льготы:
Могу я использовать абонируемый почтовый ящик в Вашем офисе для получения обычной почты, корреспонденции, счетов, подписки из Москвы или из России?
Конечно. Абонентская плата у нас дешевле, чем на Почте России. В данном случае, кроме абонентской платы Вы больше ничего не платите.
Мне нужно отправить посылку за рубеж. Чем услуги IPS по отправке отличаются от других курьерских компаний?
У меня 4 маленьких посылки. Вы сможете упаковать эти посылки в одну?
Cможем. Мы обеспечим консолидацию посылок. Для постоянных клиентов (абонирующих почтовый ящик) – эта услуга бесплатная.
Каким образом я могу оплатить доставку?
На данный момент доступны наличный и безналичный способы оплаты.
Какая компенсация мне будет выплачена в случае потери посылки?
Наша доставка имеет высокую степень надежности. Однако если такое случилось и посылка была застрахована – полная застрахованная сумма.
Как долго занимает доставка посылки?
Обычно доставка занимает от 7 до 12 дней со дня поступления посылки на наш склад в соответствующей стране.
Могу ли я хранить мою посылку на вашем складе в США/Великобритании/Германии в течение 1-2 месяцев? Взимается ли за это дополнительная плата?
Если Вы не абонируете почтовый ящик компания IPS будет хранить бесплатно Вашу посылку только в течение 7 дней с момента поступления на склад. В случае хранения посылки свыше 7 дней взимается дополнительная плата. IPS оставляет за собой право по своему усмотрению распоряжаться посылками, которые хранятся на складе более чем на 60 дней, владельцы которых не осуществили оплату хранения.
Каковы преимущества доставки с компанией IPS?
Преимущества доставки с компанией IPS:
Какую информацию я должен указать в поле «Адрес доставки» при покупке товаров в интернет-магазинах?
Вы должны ввести: адрес нашего зарубежного офиса, предоставленный Вам нашей компанией, Ваши Фамилию и Имя, номер Вашего почтового ящика.
Должен ли я что-то Вам сообщить после совершения покупки и отправки посылки на предоставленный мне адрес?
После осуществления заказа необходимо сообщить нам о совершенном заказе, предоставить данные заказа – описание вложения, его вес, стоимость. Эта информация необходима для обработки Ваших посылок.
Существуют ли ограничения возможных вложений?
С компанией IPS вы можете отправить посылку с любым вложением, не запрещенным законодательством Российской Федерации.
К запрещенным вложениям относятся:
С полным перечнем запрещенных вложений вы сможете ознакомиться .
Перед тем как сделать покупку в интернет-магазине, пожалуйста, убедитесь, что ваша покупка не относится к категории опасных грузов.
Гарантирует ли IPS подлинность и качество приобретенного мною продукта?
IPS не несет ответственности перед клиентом за подлинность и качество приобретенного им товара. В целях собственной безопасности, пожалуйста, приобретайте товары только в проверенных интернет-магазинах.
Как правильно упаковать посылку?
Тем не менее, если это необходимо, пожалуйста, обеспечьте надлежащую упаковку вашего отправления, либо проинформируйте сотрудников IPS о необходимости дополнительной упаковки вашей посылки.
Мы не несем ответственность за любые убытки и повреждения, которые могут возникнуть во время обработки, перевозки или доставки вследствие ненадлежащей упаковки посылки отправителем.
Какие документы необходимо предоставить для подтверждения оценочной стоимости отправки?
Необходимо предоставить инвойс, подготовленный отправителем, указанные в нем суммы должны включать все налоги, а также все другие возможные сборы.
В каких интернет-магазинах я могу совершать покупки?
Что делать, если продавец выслал не тот товар / не правильное количество товара?
Так как компания IPS осуществляет только доставку вашей посылки в Россию, все вопросы, касательно комплектации и соответствия товара, а так же возможность обмена, либо возврата необходимо решать непосредственно с продавцом или отправителем.
Я хочу приобрести ювелирные изделия из драгоценных металлов с драгоценными камнями. Это возможно?
Нет. Мы не доставляем изделия из драгоценных металлов и/или с драгоценными камнями.
Когда я буду знать конечную стоимости доставки?
Только после того, как посылка поступит на наш, выбранный Вами, зарубежный склад.
Как только ваша посылка будет обработана, вы будете уведомлены по электронной почте относительно сроков доставки и конечной стоимости доставки. Вашей посылке будет присвоен персональный номер, вы сможете, следуя инструкциям в письме, оплатить стоимость доставки и отследить статус своего отправления.
В случае, если вы хотите произвести консолидацию вашего отправления, необходимо производить оплату после окончательного формирования посылки.
Клиенту, абонирующему почтовый ящик, не нужно совершать никаких оплат до получения своей корреспонденции/посылок в московском офисе IPS.
Если я решил отказаться от доставки в Россию посылки, которая пришла на мое имя в зарубежный офис IPS, будут ли с меня удержаны какие-то суммы, если будет необходимо вернуть посылку отправителю или уничтожить её?
Если по какой-либо причине вы решили остановить доставку в Россию вашей посылки, пожалуйста, срочно переговорите с вашим отправителем, чтобы он не отправлял на адрес IPS вашу посылку.
В случае, если посылка все же пришла на адрес склада IPS, мы можем по вашему указанию, отправить посылку обратно (или переправить на другой адрес) с удержанием 10$ административного сбора, а также 100% стоимости затрат на возврат/доставку посылки.
Так же мы можем утилизировать посылку с удержанием 10$ административного сбора (для посылок, не превышающих 15 кг). В случае хранения посылки более, чем 21 день, IPS взимает оплату в размере $.50 в день за одну посылку.
Каков минимальный оплачиваемый вес доставляемой посылки?
Для клиентов, абонирующих почтовый ящик - минимальный оплачиваемый вес составляет 1 фунт с последующим шагом в 0,1 фунт.
В данной статье я хотел бы рассмотреть различные техники поиска информации о VoIP-устройствах в сети, а затем продемонстрировать несколько атак на VoIP.
В последние несколько лет наблюдались высокие темпы внедрения IP-телефонии (VoIP). Большинство организаций, внедривших VoIP, либо игнорируют проблемы безопасности VoIP и ее реализации, либо попросту не знают о них. Как и любая другая сеть, сеть VoIP чувствительна к неправильной эксплуатации. В данной статье я хотел бы рассмотреть различные техники поиска информации о VoIP-устройствах в сети, а затем продемонстрировать несколько атак на VoIP. Я сознательно не стал спускаться до деталей уровня протокола, поскольку данная статья предназначена для пентестеров, которые хотят для начала попробовать основные приемы. Однако я настоятельно рекомендую изучить протоколы, используемые в VoIP-сетях.
Чтобы продемонстрировать проблемы безопасности VoIP в рамках данной статьи, я использовал следующую конфигурацию лаборатории:

Рисунок 1
Рассмотрим схему лаборатории, представленную выше. Это - типичная конфигурация VoIP-сети небольшой организации с маршрутизатором, который выделяет IP-адреса устройствам, IP-PBX системе и пользователям. Если пользователь A данной сети захочет связаться с B , произойдет следующее:
Теперь, когда у нас есть ясная картина взаимодействия, давайте перейдем к развлекательной части - атакам на VoIP.
Поиск устройств (enumerating) - лежит в основе каждой успешной атаки/пентеста, поскольку он обеспечивает атакующего как необходимыми подробностями, так и общим представлением о конфигурации сети. VoIP - не исключение. В VoIP-сети нам, как атакующим, будет полезна информация о VoIP-шлюзах/серверах, IP-PBX системах, клиентских программных и VoIP-телефонах и номерах пользователей (экстеншенах). Давайте посмотрим на некоторые широко используемые инструменты для поиска устройств и создания отпечатков (fingerprints). Для упрощения демонстрации предположим, что нам уже известны IP-адреса устройств.
Smap iv сканирует отдельный IP-адрес или подсеть на предмет включенных SIP-устройств. Давайте используем smap против IP-PBX сервера. Рисунок 2 показывает, что мы смогли найти сервер и получить информацию о его User-Agent.

Рисунок 2
Svmap - другой мощный сканер из набора инструментов sipvicious v . Данный инструмент позволяет выставить тип запроса, использующийся при поиске SIP-устройств. Тип запроса по умолчанию - OPTIONS. Давайте запустим сканер для пула из 20 адресов. Как видно, svmap может обнаруживать IP-адреса и информацию о User-Agent.

Рисунок 3
При поиске VoIP-устройств для определения действующих SIP-экстеншенов может помочь поиск по номерам пользователей. Svwar vi позволяет сканировать полный диапазон IP-адресов. Рисунок 4 показывает результат сканирования пользовательских номеров в диапазоне от 200 до 300. В результате получаем экстеншены пользователей, зарегистрированные на IP-PBX сервере.

Рисунок 4
Итак, мы рассмотрели процесс поиска VoIP-устройств и получили некоторые интересные детали конфигурации. Теперь давайте воспользуемся этой информацией для атаки на сеть, конфигурацию которой мы только что исследовали.
Как уже обсуждалось, VoIP-сеть подвержена множеству угроз безопасности и атак. В данной статье мы рассмотрим три критические атаки на VoIP, которые могут быть направлены на нарушение целостности и конфиденциальности VoIP-инфраструктуры.
В дальнейших разделах продемонстрированы следующие атаки:
Когда новый или существующий VoIP-телефон подсоединяется к сети, он посылает на IP-PBX сервер запрос REGISTER для регистрации ассоциированного с телефоном идентификатора пользователя/экстеншена. Этот запрос на регистрацию содержит важную информацию (вроде информации о пользователе, данных аутентификации и т. п.) которая может представлять большой интерес для атакующего или пентестера. Рисунок 5 показывает перехваченный пакет запроса на аутентификацию по протоколу SIP. Перехваченный пакет содержит лакомую для атакующего информацию. Давайте используем данные пакета для атаки на аутентификацию.

Рисунок 5

Рисунок 6
Шаг 1: Для упрощения демонстрации предположим, что у нас есть физический доступ к VoIP-сети. Теперь, используя инструменты и техники, описанные в предыдущих разделах статьи, мы проведем сканирование и поиск устройств, чтобы получить следующую информацию:
Шаг 2: Давайте перехватим несколько запросов на регистрацию с помощью wireshark vii . Мы сохраним их в файле с именем auth.pcap. Рисунок 7 показывает файл wireshark с результатами перехвата (auth.pcap).

Рисунок 7
Шаг 3:
Теперь мы используем набор инструментов sipcrack viii . Набор входит в состав Backtrack и находится в директории /pentest/VoIP. Рисунок 8 показывает инструменты из набора sipcrack.
Рисунок 8
Шаг 4: Используя sipdump, давайте выгрузим данные аутентификации в файл с именем auth.txt. Рисунок 9 показывает файл захвата wireshark, содержащий аутентификационные данные пользователя 200.

Рисунок 9
Шаг 5: Эти данные аутентификации включают в себя идентификатор пользователя, SIP-экстеншен, хэш пароля (MD5) и IP-адрес жертвы. Теперь мы используем sipcrack, чтобы взломать хэши паролей с помощью атаки по заготовленному словарю. Рисунок 10 показывает, что в качестве словаря для взлома хэшей используется файл wordlist.txt. Мы сохраним результаты взлома в файле с именем auth.txt.

Рисунок 10
Шаг 6: Замечательно, теперь у нас есть пароли для экстеншенов! Мы можем использовать эту информацию, чтобы перерегистрироваться на IP-PBX сервере с нашего собственного SIP-телефона. Это позволит нам выполнять следующие действия:
Каждое сетевое устройство имеет уникальный MAC-адрес. Как и остальные сетевые устройства, VoIP телефоны уязвимы к спуфингу MAC/ARP. В данном разделе мы рассмотрим снифинг активных голосовых звонков путем прослушивания и записи действующих разговоров по VoIP.

Рисунок 11
Шаг 1: В целях демонстрации, давайте предположим, что мы уже определили IP-адрес жертвы, используя ранее описанные техники. Далее, используя ucsniff ix как средство ARP-спуфинга, мы подменим MAC-адрес жертвы.
Шаг 2: Важно определить MAC-адрес цели, который требуется подменить. Хотя ранее упоминавшиеся инструменты были способны определять MAC-адрес автоматически, хорошей практикой будет определить MAC независимо, отдельным способом. Давайте используем для этого nmap x . Рисунок 12 показывает результаты сканирования IP-адреса жертвы и полученный в результате MAC-адрес.
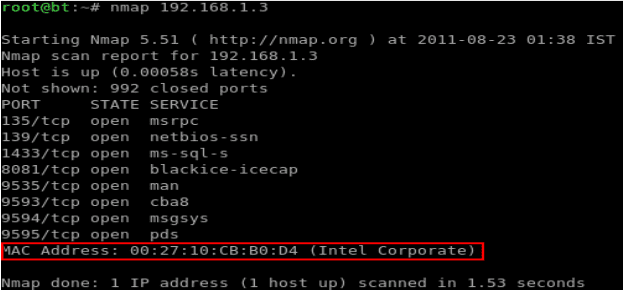
Рисунок 12
Шаг 3: Теперь, когда у нас есть MAC-адрес жертвы, давайте используем ucsniff, чтобы подменить ее MAC. ucsniff поддерживает несколько режимов спуфинга (режим наблюдения, режим изучения и режим MiTM, т. е. «человек-посередине»). Давайте используем режим MiTM, указав IP-адрес жертвы и SIP-экстеншен в файле с именем targets.txt. Этот режим гарантирует, что прослушиваются только звонки (входящие и исходящие) жертвы (пользователь A ), не затрагивая другой трафик в сети. Рисунки 13 и 14 показывают, что ucsniff подменил MAC пользователя A (в ARP-таблице).

Рисунок 13

Рисунок 14
Шаг 4: Мы успешно подменили MAC-адрес жертвы и теперь готовы прослушивать входящие и исходящие звонки пользователя A по VoIP-телефону.
Шаг 5: Теперь, когда пользователь B звонит пользователю A и начинает диалог, ucsniff принимается записывать их беседу. Когда звонок завершается, ucsniff сохраняет записанную беседу целиком в wav-файл. Рисунок 15 показывает, что ucsniff обнаружил новый звонок с экстеншена 200 на экстеншен 202.
Рисунок 15
Шаг 6: Когда мы закончим, мы вызывем ucsniff снова с ключом -q, чтобы прекратить спуфинг MAC в системе и, таким образом, гарантировать, что после завершения атаки все встало на свои места.
Шаг 7: Сохраненный аудиофайл можно проиграть, используя любой известный медиаплеер вроде windows media player.
Это одна из простейших атак на VoIP-сети. Спуфинг ID абонента соответствует сценарию, когда неизвестный пользователь может выдать себя за легального пользователя VoIP-сети. Для реализации данной атаки может быть достаточно легких изменений в INVITE запросе. Существует множество способов формирования искаженных нужным образом SIP INVITE сообщений (с помощью scapy, SIPp и т. д.). Для демонстрации используем вспомогательный модуль sip_invite_spoof из фреймворка metasploit xi .

Рисунок 16
Шаг 1: Давайте запустим metasploit и загрузим вспомогательный модуль voip/sip_invite_spoof.
Шаг 2: Далее, установим значение опции MSG в User B . Это даст нам возможность выдавать себя за пользователя B . Пропишем также IP-адрес пользователя A в опции RHOSTS. После настройки модуля, мы запускаем его. Рисунок 17 демонстрирует все настройки конфигурации.

Рисунок 17
Шаг 3: Вспомогательный модуль будет посылать измененные invite-запросы жертве (пользователю A ). Жертва будет получать звонки с моего VoIP телефона и отвечать на них, думая, что говорит с пользователем B . Рисунок 18 показывает VoIP-телефон жертвы (A ), которая получает звонок якобы от пользователя B (а на самом деле от меня).

Рисунок 18
Шаг 4: Теперь A считает, что поступил обычный звонок от B и начинает говорить с тем, кто представился как User B .
Множество существующих угроз безопасности относится и к VoIP. Используя поиск устройств, можно получить критичную информацию, относящуюся к VoIP-сети, пользовательским идентификаторам/экстеншенам, типам телефонов и т. д. С помощью специальных инструментов, возможно проводить атаки на аутентификацию, похищать VoIP звонки, подслушивать, манипулировать звонками, рассылать VoIP-спам, проводить VoIP-фишинг и компрометацию IP-PBX сервера.
Я надеюсь, что данная статья была достаточно информативной, чтобы обратить внимание на проблемы безопасности VoIP. Я бы хотел попросить читателей отметить, что в данной статье не обсуждались все возможные инструменты и техники, использующиеся для поиска VoIP-устройств в сети и пентестинга.
Сохил Гарг - пентестер в PwC. Области его интересов включают разработку новых векторов атак и тестирование на проникновение в охраняемых средах. Он участвует в оценках защищенности различных приложений. Он докладывал о проблемах безопасности VoIP на конференциях CERT-In, которые посещали высокопоставленные правительственные чиновники и представители ведомств обороны. Недавно он обнаружил уязвимость в продукте крупной компании, дающую возможность повышения привилегий и прямого доступа к объекту.
17.03.1996 Павел Храмцов
Пользователям Internet хорошо известны названия таких сервисов и информационных служб, как Lycos, AltaVista, Yahoo, OpenText, InfoSeek и др. - без услуг этих систем сегодня практически нельзя найти что-либо полезное в море информационных ресурсов Сети. Что собой представляют эти сервисы изнутри, как они устроены, почему результат поиска в терабайтных массивах информации осуществляется достаточно быстро и как устроено ранжирование документов при выдаче - все это обычно остается за кадром. Тем не менее без правильного планирования стратегии поиска, знакомства с основными положениями теории ИПС (Информационно-Поисковых Систем), насчитывающей уже двадцатилетнюю историю, трудно эффективно использовать даже такие скорострельные сервисы, как AltaVista или Lycos. Архитектура современных ИПС для WWW Информационные ресурсы и их представление в ИПС Индекс поиска Информационно-поисковый язык системы Интерфейс системы Заключение Литература Пользователям Internet уже хорошо известны названия таких сервисов
Пользователям Internet хорошо известны названия таких сервисов и информационных служб, как Lycos, AltaVista, Yahoo, OpenText, InfoSeek и др. - без услуг этих систем сегодня практически нельзя найти что-либо полезное в море информационных ресурсов Сети. Что собой представляют эти сервисы изнутри, как они устроены, почему результат поиска в терабайтных массивах информации осуществляется достаточно быстро и как устроено ранжирование документов при выдаче - все это обычно остается за кадром. Тем не менее без правильного планирования стратегии поиска, знакомства с основными положениями теории ИПС (Информационно-Поисковых Систем), насчитывающей уже двадцатилетнюю историю, трудно эффективно использовать даже такие скорострельные сервисы, как AltaVista или Lycos.
Информационно-поисковые системы появились на свет достаточно давно. Теории и практике построения таких систем посвящено множество статей, основная масса которых приходится на конец 70-х - начало 80-х годов. Среди отечественных источников следует выделить научно-технический сборник "Научно-техническая информация. Серия 2", который выходит до сих пор. На русском языке издана так же и "библия" по разработке ИПС - "Динамические библиотечно-информационные системы" Ж. Солтона , в которой рассмотрены основные принципы построения информационно-поисковых систем и моделирования процессов их функционирования. Таким образом, нельзя сказать, что с появлением Internet и бурным вхождением его в практику информационного обеспечения появилось нечто принципиально новое, чего не было раньше. Если быть точным, то ИПС в Internet - это признание того, что ни иерархическая модель Gopher, ни гипертекстовая модель World Wide Web еще не решают проблему поиска информации в больших объемах разнородных документов. И на сегодняшний день нет другого способа быстрого поиска данных, кроме поиска по ключевым словам.
При использовании иерархической модели Gopher приходится довольно долго бродить по дереву каталогов, пока не встретишь нужную информацию. Эти каталоги должны кем-то поддерживаться, и при этом их тематическое разбиение должно совпадать с информационными потребностями пользователя. Учитывая анархичность Internet и огромное количество всевозможных интересов у пользователей Сети, понятно, что кому-то может и не повезти и в сети не будет каталога, отражающего конкретную предметную область. Именно по этой причине для множества серверов Gopher, называемого GopherSpace была разработана информационно-поисковая программа Veronica (Very Easy Rodent-Oriented Net-wide Index of Computerized Archives).
Аналогичное развитие событий наблюдается и в World Wide Web. Собственно еще в 1988 году в специальном выпуске журнала "Communication of the ACM" среди прочих проблем разработки гипертекстовых систем и их использования Франк Халаз назвал в качестве первоочередной задачи для следующего поколения систем этого типа назвал проблему организации поиска информации в больших гипертекстовых сетях. До сих пор многие идеи, высказанные в той статье, не нашли еще своей реализации. Естественно, что система, предложенная Бернерсом-Ли и получившая такое широкое распространение в Internet, должна была столкнуться с теми же проблемами, что и ее локальные предшественники. Реальное подтверждение этому было продемонстрировано на второй конференции по World Wide Web осенью 1994 года, на которой были представлены доклады о разработке информационно-поисковых систем для Web, а система World Wide Web Worm, разработанная Оливером МакБрайном из Университета Колорадо, получила приз как лучшее навигационное средство. Следует также отметить, что все-таки долгая жизнь суждена отнюдь не чудесным программам талантливых одиночек, а средствам, являющимся результатом планового и последовательного движения научных и производственных коллективов к поставленной цели. Рано или поздно этап исследований заканчивается, и наступает этап эксплуатации систем, а это уже совсем другой род деятельности. Именно такая судьба ожидала два других проекта, представленных на той же конференции: Lycos, поддерживаемый компанией Microsoft, и WebCrawler, ставший собственностью America On-line.
Разработка новых информационных систем для Web не завершена. Причем как на стадии написания коммерческих систем, так и на стадии исследований. За прошедшие два года снят только верхний слой возможных решений. Однако многие проблемы, которые ставит перед разработчиками ИПС Internet, не решены до сих пор. Именно этим обстоятельством и вызвано появление проектов типа AltaVista компании Digital , главной целью которого является разработка программных средств информационного поиска для Web и подбор архитектуры для информационного сервера Web.
Прежде чем описать проблемы построения информационно-поисковых систем Web и пути их решения рассмотрим типовую схему такой системы. В различных публикациях, посвященных конкретным системам, например , приводятся схемы, которые отличаются друг от друга только способом применения конкретных программных решений, а не принципом организации различных компонентов системы. Поэтому рассмотрим эту схему на примере, взятом из работы (рис.).
Рис. Типовая схема информационно-поисковой системы.
Client (клиент) на этой схеме - это программа просмотра конкретного информационного ресурса. Наиболее популярны сегодня мультипротокольные программы типа Netscape Navigator. Такая программа обеспечивает просмотр документов WWW, Gopher, Wais, FTP-архивов, почтовых списков рассылки и групп новостей Usenet. В свою очередь все эти информационные ресурсы являются объектом поиска информационно-поисковой системы.
User interface (пользовательский интерфейс) - это не просто программа просмотра, в случае информационно-поисковой системы под этим словосочетанием понимают также способ общения пользователя с поисковым аппаратом: системой формирования запросов и просмотров результатов поиска.
Search engine (поисковая машина) - служит для трансляции запроса на информационно-поисковом языке (ИПЯ), в формальный запрос системы, поиска ссылок на информационные ресурсы Сети и выдачи результатов этого поиска пользователю.
Index database (индекс базы данных) - индекс, который является основным массивом данных ИПС и служит для поиска адреса информационного ресурса. Архитектура индекса устроена таким образом, чтобы поиск происходил максимально быстро и при этом можно было бы оценить ценность каждого из найденных информационных ресурсов сети.
Queries (запросы пользователя) - сохраняются в его (пользователя) личной базе данных. На отладку каждого запроса уходит достаточно много времени, и поэтому чрезвычайно важно запоминать запросы, на которые система дает хорошие ответы.
Index robot (робот-индексировщик) - служит для сканирования Internet и поддержания базы данных индекса в актуальном состоянии. Эта программа является основным источником информации о состоянии информационных ресурсов сети.
WWW sites - это весь Internet или точнее - информационные ресурсы, просмотр которых обеспечивается программами просмотра.
Рассмотрим теперь назначение и принципу построения каждого из этих компонентов более подробно и определим, в чем отличие данной системы от традиционной ИПС локального типа.
Как видно из рисунка, документальным массивом ИПС Internet является все множество документов шести основных типов: WWW-страницы, Gopher-файлы, документы Wais, записи архивов FTP, новости Usenet и статьи почтовых списков рассылки. Все это довольно разнородная информация, которая представлена в виде различных, никак несогласованных друг с другом форматов данных: тексты, графическая и аудиоинформация и вообще все, что имеется в указанных хранилищах. Естественно возникает вопрос - как информационно-поисковая система должна со всем этим работать?
В традиционных системах используется понятие поискового образа документа - ПОД. Обычно, этим термином обозначают нечто, заменяющее собой документ и использующееся при поиске вместо реального документа. Поисковый образ является результатом применения некоторой модели информационного массива документов к реальному массиву. Наиболее популярной моделью является векторная модель , в которой каждому документу приписывается список терминов, наиболее адекватно отражающих его смысл. Если быть более точным, то документу приписывается вектор размерности, равный числу терминов, которыми можно воспользоваться при поиске. При булевой векторной модели элемент вектора равен 1 или 0, в зависимости от наличия или отсутствия термина в ПОД. В более сложных моделях термины взвешиваются - элемент вектора равен не 1 или 0, а некоторому числу (весу), отражающему соответствие данного термина документу. Именно последняя модель стала наиболее популярной в ИПС Internet .
Вообще говоря, существуют и другие модели описания документов: вероятностная модель информационных потоков и поиска и модель поиска в нечетких множествах . Не вдаваясь в подробности, имеет смысл обратить внимание на то, что пока только линейная модель применяется в системах Lycos, WebCrawler, AltaVista, OpenText и AliWeb. Однако ведутся исследования по применению и других моделей, результаты которых отражены в работах . Таким образом, первая задача, которую должна решить ИПС, - это приписывание списка ключевых слов документу или информационному ресурсу. Именно эта процедура и называется индексированием. Часто, однако, индексированием называют составление файла инвертированного списка, в котором каждому термину индексирования ставится в соответствие список документов в которых он встречается. Такая процедура является только частным случаем, а точнее, техническим аспектом создания поискового аппарата ИПС. Проблема, связанная с индексированием, заключается в том, что приписывание поискового образа документу или информационному ресурсу опирается на представление о словаре, из которого эти термины выбираются, как о фиксированной совокупности терминов. В традиционных системах существовало разбиение на системы с контролируемым словарем и системы со свободным словарем. Контролируемый словарь предполагал ведение некоторой лексической базы данных, добавление терминов в которую производилось администратором системы, и все новые документы могли быть заиндексированы только теми терминами, которые были в этой базе данных. Свободный словарь пополнялся автоматически по мере появления новых документов. Однако на момент актуализации словарь также фиксировался. Актуализация предполагала полную перезагрузку базы данных. В момент этого обновления перегружались сами документы, и обновлялся словарь, а после его обновления производилась переиндексация документов. Процедура актуализации занимала достаточно много времени и доступ к системе в момент ее актуализации закрывался.
Теперь представим себе возможность такой процедуры в анархичном Internet, где ресурсы появляются и исчезают ежедневно. При создании программы Veronica для GopherSpace предполагалось, что все серверы должны быть зарегистрированы, и таким образом велся учет наличия или отсутствия ресурса. Veronica раз в месяц проверяла наличие документов Gopher и обновляла свою базу данных ПОД для документов Gopher. В WWW ничего подобного нет. Для решения этой задачи используются программы сканирования сети или роботы-индексировщики . Разработка роботов - это довольно нетривиальная задача; существует опасность зацикливания робота или его попадания на виртуальные страницы. Робот просматривает сеть, находит новые ресурсы, приписывает им термины и помещает в базу данных индекса. Главный вопрос заключается в том, что за термины приписывать документам, откуда их брать, ведь ряд ресурсов вообще не является текстом. Сегодня роботы обычно используют для индексирования следующие источники для пополнения своих виртуальных словарей: гипертекстовые ссылки, заголовки, заглавия (H1,H2), аннотации, списки ключевых слов, полные тексты документов, а также сообщения администраторов о своих Web-страницах . Для индексирования telnet, gopher, ftp, нетекстовой информации используются главным образом URL, для новостей Usenet и почтовых списков поля Subject и Keywords. Наибольший простор для построения ПОД дают HTML документы. Однако не следует думать, что все термины из перечисленных элементов документов попадают в их поисковые образы. Очень активно применяются списки запрещенных слов (stop-words), которые не могут быть употреблены для индексирования, общих слов (предлоги, союзы и т.п.). Таким образом даже то, что в OpenText, например, называется полнотекстовым индексированием реально является выбором слов из текста документа и сравнением с набором различных словарей, после которого термин попадает в ПОД, а потом и в индекс системы. Для того чтобы не раздувать словарей и индексов (индекс системы Lycos уже сегодня равен 4 Тбайт), применяется такое понятие, как вес термина . Документ обычно индексируется через 40 - 100 наиболее "тяжелых" терминов.
После того как ресурсы заиндексированы и система составила массив ПОД, начинается построение поискового аппарата. Совершенно очевидно, что лобовой просмотр файла или файлов ПОД займет много времени, что абсолютно не приемлемо для интерактивной системы WWW. Для ускорения поиска строится индекс, которым в большинстве систем является набор связанных между собой файлов, ориентированных на быстрый поиск данных по запросу. Структура и состав индексов различных систем могут отличаться друг от друга и зависят от многих факторов: размер массива поисковых образов, информационно-поисковый язык, размещения различных компонентов системы и т.п. Рассмотрим структуру индекса на примере системы , для которой можно реализовывать не только примитивный булевый, но и контекстный и взвешенный поиск, а также ряд других возможностей, отсутствующие во многих поисковых системах Internet, например Yahoo. Индекс рассматриваемой системы состоит из таблицы идентификаторов страниц (page-ID), таблицы ключевых слов (Keyword-ID), таблицы модификации страниц, таблицы заголовков, таблицы гипертекстовых связей, инвертированного (IL) и прямого списка (FL).
Page-ID отображает идентификаторы страниц в их URL, Keyword-ID - каждое ключевое слов в уникальный идентификатор этого слова, таблица заголовков - идентификатор страницы в заголовок страницы, таблица гипертекстовых ссылок - идентификатор страниц в гипертекстовую ссылку на эту страницу. Инвертированный список ставит в соответствие каждому ключевому слову документа список пар - идентификатор страницы, позиция слова в странице. Прямой список - это массив поисковых образов страниц. Все эти файлы так или иначе используются при поиске, но главным среди них является файл инвертированного списка. Результат поиска в данном файле - это объединение и/или пересечение списков идентификаторов страниц. Результирующий список, который преобразовывается в список заголовков, снабженных гипертекстовыми ссылками возвращается пользователю в его программу просмотра Web. Для того чтобы быстро искать записи инвертированного списка, над ним надстраивается еще несколько файлов, например, файл буквенных пар с указанием записей инвертированного списка, начинающихся с этих пар. Кроме этого, применяется механизм прямого доступа к данным - хеширование. Для обновления индекса используется комбинация двух подходов. Первый можно назвать коррекцией индекса "на ходу" с помощью таблицы модификации страниц. Суть такого решения довольно проста: старая запись индекса ссылается на новую, которая и используется при поиске. Когда число таких ссылок становится достаточным для того, чтобы ощутить это при поиске, то происходит полное обновление индекса - его перезагрузка. Эффективность поиска в каждой конкретной ИПС определяется исключительно архитектурой индекса. Как правило, способ организации этих массивов является "секретом фирмы" и ее гордостью. Для того чтобы убедиться в этом, достаточно почитать материалы OpenText .
Индекс - это только часть поискового аппарата, скрытая от пользователя. Второй частью этого аппарата является информационно-поисковый язык (ИПЯ), позволяющий сформулировать запрос к системе в простой и наглядной форме. Уже давно осталась позади романтика создания ИПЯ, как естественного языка, - именно этот подход использовался в системе Wais на первых стадиях ее реализации. Если даже пользователю предлагается вводить запросы на естественном языке, то это еще не значит, что система будет осуществлять семантический разбор запроса пользователя. Проза жизни заключается в том, что обычно фраза разбивается на слова, из которых удаляются запрещенные и общие слова, иногда производится нормализация лексики, а затем все слова связываются либо логическим AND, либо OR. Таким образом, запрос типа:
>Software that is used on Unix Platform
будет преобразован в:
>Unix AND Platform AND Software
что будет означать примерно следующее: "Найди все документы, в которых слова Unix, Platform и Software встречаются одновременно ".
Возможны и варианты. Так, в большинстве систем фраза "Unix Platform" будет опознана как ключевая фраза и не будет разделяться на отдельные слова. Другой подход заключается в вычислении степени близости между запросом и документом. Именно этот подход используется в Lycos. В этом случае в соответствии с векторной моделью представления документов и запросов вычисляется их мера близости. Сегодня известно около дюжины различных мер близости. Наиболее часто применяется косинус угла между поисковым образом документа и запросом пользователя. Обычно эти проценты соответствия документа запросу и выдаются в качестве справочной информации при списке найденных документов.
Наиболее развитым языком запросов из современных ИПС Internet обладает Alta Vista. Кроме обычного набора AND, OR, NOT эта система позволяет использовать еще и NEAR, позволяющий организовать контекстный поиск. Все документ в системе разбиты на поля, поэтому в запросе можно указать, в какой части документа пользователь надеется увидеть ключевое слово: ссылка, заглавие, аннотация и т.п. Можно также задавать поле ранжирования выдачи и критерий близости документов запросу.
Важным фактором является вид представления информации в программе-интерфейсе. Различают два типа интерфейсных страниц: страницы запросов и страницы результатов поиска.
При составлении запроса к системе используют либо меню - ориентированный подход, либо командную строку. Первый позволяет ввести список терминов, обычно разделяемых пробелом, и выбрать тип логической связи между ними. Логическая связь распространяется на все термины. На схеме из рисунка указаны сохраненные запросы пользователя - в большинстве систем это просто фраза на ИПЯ, которую можно расширить за счет добавления новых терминов и логических операторов. Но это только один способ использования сохраненных запросов, называемый расширением или уточнением запроса. Для выполнения этой операции традиционная ИПС хранит не запрос как таковой, а результат поиска - список идентификаторов документов, который объединяется/пересекается со списком, полученным при поиске документов по новым терминам. К сожалению, сохранение списка идентификаторов найденных документов в WWW не практикуется, что было вызвано особенностью протоколов взаимодействия программы-клиента и сервера, не поддерживающих сеансовый режим работы.
Итак, результат поиска в базе данных ИПС - это список указателей на удовлетворяющие запросу документы. Различные системы представляют этот список по-разному. В некоторых выдается только список ссылок, а в таких, как Lycos, Alta Vista и Yahoo, дается еще и краткое описание, которое заимствуется либо из заголовков, либо из тела самого документа. Кроме этого, система сообщает, на сколько найденный документ соответствует запросу. В Yahoo, например, это количество терминов запроса, содержащихся в ПОД, в соответствии с которым ранжируется результат поиска. Система Lycos выдает меру соответствия документа запросу, по которой производится ранжирование.
При обзоре интерфейсов и средств поиска нельзя пройти мимо процедуры коррекции запросов по релевантности . Релевантность - это мера соответствия найденного системой документа потребности пользователя. Различают формальную релевантность и реальную. Первую вычисляет система, и на основании чего ранжируется выборка найденных документов. Вторая - это оценка самим пользователем найденных документов. Некоторые системы имеют для этого специальное поле , где пользователь может отметить документ как релевантный. При следующей поисковой итерации запрос расширяется терминами этого документа, а результат снова ранжируется. Так происходит до тех пор, пока не наступит стабилизация, означающая, что ничего лучше, чем полученная выборка, от данной системы не добьешься.
Кроме ссылок на документы в списке, полученном пользователем, могут оказаться ссылки на части документов или на их поля. Это происходит при наличии ссылок типа http://host/path#mark или ссылок по схеме WAIS. Возможны ссылки и на скрипты, но обычно такие ссылки роботы пропускают, и система их не индексирует. Если с http-ссылками все более или менее понятно, то ссылки WAIS - это гораздо более сложные объекты. Дело в том, что WAIS реализует архитектуру распределенной информационно-поисковой системы, при которой одна ИПС, например Lycos, строит поисковый аппарат над поисковым аппаратом другой системы - WAIS. При этом серверы WAIS имеют свои собственные локальные базы данных. При загрузке документов в WAIS администратор может описать структуру документов, разбив их на поля, и хранить документы в виде одного файла. Индекс WAIS будет ссылаться на отдельные документы и их поля как на самостоятельные единицы хранения, программа просмотра ресурсов Internet в этом случае должна уметь работать с протоколом WAIS, чтобы получить доступ к этим документам.
В обзорной статье были рассмотрены основные элементы информационно-поисковых систем и принципы их построения. Сегодня ИПС являются наиболее мощным механизмом поиска сетевых информационных ресурсов Internet. К сожалению, в российском секторе Internet пока не наблюдается активного изучения этой проблемы за исключением, может быть, проекта LIBWEB, финансируемого РФФИ и системы "Паук", которая работает недостаточно надежно. Наибольшим опытом разработки такого сорта систем безусловно обладает ВИНИТИ, но здесь работа сосредоточена пока на размещении своих собственных ресурсов в Сети, что принципиально отличается от информационно-поисковых систем Internet типа Lycos, OpenText, Alta Vista, Yahoo, InfoSeek и т.п. Казалось бы, что такая работа могла быть сосредоточена в рамках таких проектов, как Россия On-line компании SovamTeleport, но здесь мы пока наблюдаются ссылки на чужие поисковые машины. Развитие ИПС для Internet в США началось два года назад, учитывая отечественные реалии и темпы развития технологий Сети в России, можно надеяться, что у нас еще все впереди.
1.
Дж. Солтон. Динамические библиотечно-информационные системы. Мир, Москва, 1979.
2. Frank G. Halasz. Reflection notecards: seven issues for the next generation of hypermedia systems. Communication of the acm, V31, N7, 1988, p.836-852.
3. Tim Berners-Lee. World Wide Web: Proposal for HyperText Project. 1990.
4. Alta Vista . Digital Equipment Corporation, 1996.
5. Brain Pinkerton. Finding What People Want: Experiences with the WebCrawler .
6. Bodi Yuwono, Savio L.Lam, Jerry H.Ying, Dik L.Lee. .
7. Martin Bartschi. An Overview of Information Retrieval Subjects. IEEE Computer, N5, 1985,p.67-84.
8. Michel L. Mauldin, John R.R. Leavitt. Web Agent Related Research at the Center for Machine Translation .
9. Ian R.Winship. World Wide Web searching tools -an evaluation . VINE (99).
10. G.Salton, C.Buckley. Term-Weighting Approachs in Automatic Text Retrieval. Information Processing & Management, 24(5), pp. 513-523, 1988.
11. Open Text Corporation Releases Industry"s Highest Performance Text Retrieval System.
Павел Храмцов ([email protected]) - независимый эксперт, (Москва).
ИПС (информационно-поисковая система) – это система, обеспечивающая поиск и отбор необходимых данных в специальной базе с описаниями источников информации (индексе) на основе информационно-поискового языка и соответствующих правил поиска.
Главной задачей любой ИПС является поиск информации релевантной информационным потребностям пользователя. Очень важно в результате проведенного поиска ничего не потерять, то есть найти все документы, относящиеся к запросу, и не найти ничего лишнего. Поэтому вводится качественная характеристика процедуры поиска – релевантность.
Релевантность – это соответствие результатов поиска сформулированному запросу.
По пространственному масштабу ИПС можно разделить на локальные, глобальные, региональные и специализированные. Локальные поисковые системы могут быть разработаны для быстрого поиска страниц в масштабе отдельного сервера.
Региональные ИПС описывают информационные ресурсы определенного региона, например, русскоязычные страницы в Интернете. Глобальные поисковые системы в отличие от локальных стремятся объять необъятное – по возможности наиболее полно описать ресурсы всего информационного пространства сети Интернет.
Кроме того, ИПС также могут специализироваться по поиску различных источников информации, например, документов WWW, файлов, адресов и т.д.
Рассмотрим подробнее основные задачи, которые должны решить разработчики ИПС. Как следует из определения, ИПС для WWW проводят поиск в собственной базе (индексе) с описанием распределенных источников информации.
Следовательно, сначала нужно описать информационные ресурсы и создать индекс. Построение индекса начинается с определения начального набора URL источников информации. Затем проводится процедура индексирования.
Индексирование – описание источников информации и построение специальной базы данных (индекса ) для эффективного поиска.
В некоторых информационно-поисковых системах описание источников информации проводится персоналом ИПС, то есть, людьми, которые составляют краткую аннотацию на каждый ресурс. Затем, как правило, проводится сортировка аннотаций по темам (составление тематического каталога). Конечно, описание, составленное человеком, будет совершенно адекватно источнику. Правда, в этом случае процедура описания занимает значительный период времени, поэтому формируемый индекс имеет, как правило, ограниченный объем. Зато поиск в подобной системе можно будет проводить так же легко, как в тематических каталогах библиотек.
В ИПС второго типа процедура описания информационных ресурсов автоматизирована. Для этого разрабатывается специальная программа-робот, которая по определенной технологии обходит ресурсы, описывает их (проводит индексирование) и анализирует ссылки с текущей страницы для расширения области поиска. Как может описать документ программа? Чаще всего просто составляется список слов, которые встречаются в тексте и других частях документа, при этом учитывается частота повторения и местоположение слова, то есть, слову приписывается своеобразный весовой коэффициент в зависимости от его значимости. Например, если слово находится в названии Web-страницы, робот пометит этот факт для себя. Поскольку описание автоматизировано, затраты времени невелики, и индекс может оказаться очень большим по размеру.
Следовательно, следующей задачей для ИПС второго типа является разработка робота-индексировщика. Для поиска в системах данного типа пользователю придется научиться составлять запросы, в простейшем случае состоящие из нескольких слов. Тогда ИПС будет искать в своем индексе документы, в описаниях которых встречаются слова из запроса. Для проведения более качественного поиска необходимо разрабатывать специальный язык запросов для пользователя. В зависимости от особенностей построения модели индекса и поддерживаемого языка запросов разрабатывается механизм поиска и алгоритм сортировки результатов поиска. Поскольку индекс имеет значительный объем, количество найденных документов может оказаться достаточно большим. Следовательно, чрезвычайно важно, как поисковая машина проведет поиск и отсортирует его результаты.
Не последнее значение имеет внешний вид поисковой системы, предстающий перед пользователем, поэтому одной из задач является разработка удобного и красивого интерфейса. Наконец, исключительно важна форма представления результатов поиска, поскольку пользователю необходимо узнать как можно больше о найденном источнике информации, чтобы принять правильное решение о необходимости его посещения.
Для обращения к поисковому серверу пользователь использует стандартную программу-клиент для всемирной паутины, то есть браузер. По адресу домашней страницы ИПС пользователь работает с интерфейсом поисковой системы, который служит для общения пользователя с поисковым аппаратом системы (системой формирования запросов и просмотра результатов поиска).
Информационно-поисковые системы
Основным компонентом ИПС является поисковая машина, которая служит для перевода запроса пользователя в формальный запрос системы, поиска ссылок на информационные ресурсы и выдачи результатов поиска пользователю.
Как уже говорилось ранее, поиск осуществляется в специальной базе, именуемой индексом. Архитектура индекса устроена таким образом, чтобы поиск проходил максимально быстро, и при этом можно было отследить ценность каждого из найденных ресурсов. Некоторые системы сохраняют запросы пользователя в его личной базе данных, поскольку на отладку каждого запроса уходит много времени, и чрезвычайно важно хранить запросы, на которые получен удовлетворительный ответ.
Робот-индексировшик – программа, которая служит для сканирования Интернет и поддержки базы данных индекса в актуальном состоянии.
Web-сайты – те информационные ресурсы, доступ к которым обеспечивает ИПС.
Как известно, Web-страница – это сложный документ, состоящий из множества элементов. При описании подобного документа программой-роботом необходимо учитывать, в какой именно части Web-страницы встретилось данное слово. Источниками индексирования для документов WWW являются:
Заголовки (Title).
Заглавия.
Аннотация (Description).
Списки ключевых слов (KeyWords).
Полные тексты документов.
Кстати, поисковые системы, которые описывают абсолютно весь текст документа WWW, называются полнотекстовыми.
Для того, чтобы описать файл в ресурсе FTP используется URL. Для описания статьи в группе новостей источниками индексирования являются поля Тема (Subject) и Keywords (ключевые слова).
Во время процедуры индексирования часто производится нормализация лексики (приведение слова к базовой форме), некоторые неинформативные слова, например, союзы или предлоги, игнорируются. В каждой ИПС существует свой список называемых стоп-слов, которые игнорируются в процессе индексирования. В системах с сильно изменяемыми языками, например, русским, проводится учет морфологии.
Учет морфологии означает умение работать с различными формами слов конкретного языка.
Здесь следует отметить достаточную сложность русского языка, слова которого изменяются по числам, падежам, родам и временам, причем зачастую неожиданным образом. Например: идет, шел, пойдет, идут и т.д. Все существующие ИПС с учетом морфологии русского языка используют "Грамматический словарь русского языка", составленным Андреем Анатольевичем Зализняком. Словарь включает 90000 словарных статей, по каждому слову даются сведения о том, изменяемо ли оно, и как именно оно склоняется или спрягается.
Из вышеизложенного следует, что основными инструментами поиска информации в WWW являются ИПС.
Однако в Интернет существуют средства поиска, имеющие принципиальные отличия от рассмотренных выше ИПС. В общем случае, можно выделить следующие поисковые инструменты для WWW:
поисковые системы,
метапоисковые системы и программы ускоренного поиска.
Центральное место по праву принадлежит поисковым системам, которые в свою очередь подразделяются на каталоги, автоматические индексы (поисковые машины) и каталоги-индексы. Только поисковые системы почти в полном объеме обладают возможностями и свойствами ИПС.
Каталог – поисковая система с классифицированным по темам списком аннотаций со ссылками на web-ресурсы. Классификация, как правило, проводится людьми.
Рассмотрим особенности систем-каталогов.
Поиск в каталоге очень удобен и проводится посредством последовательного уточнения тем. Тем не менее, каталоги поддерживают возможность быстрого поиска определенной категории или страницы по ключевым словам с помощью локальной поисковой машины.
База данных ссылок (индекс) каталога обычно имеет ограниченный объем, заполняется вручную персоналом каталога. Некоторые каталоги используют автоматическое обновление индекса.
Результат поиска в каталоге представляется в виде списка, состоящего из краткого описания (аннотации) документов с гипертекстовой ссылкой на первоисточник.
Среди самых популярных зарубежных каталогов можно упомянуть: Yahoo (www.yahoo.com), Magellan (www.mckinley.com),
Российские каталоги: @Rus (www.atrus.ru); Weblist (www.weblist.ru); Созвездие интернет (www.stars.ru).
Поисковая система – система с формируемой роботом базой данных, содержащей информацию об информационных ресурсах.
Отличительной чертой поисковых систем является тот факт, что база данных, содержащая информацию об Web-страницах, статьях Usenet и т.д., формируется программой-роботом. Поиск в такой системе проводится по запросу, составляемому пользователем, состоящему из набора ключевых слов или фразы, заключенной в кавычки. Индекс формируется и поддерживается в актуальном состоянии роботами-индексировщиками.
Зарубежные поисковые машины (системы):
Google - www.google.com (примерно 38% охвата русскоязычных запросов)
Altavista- www.altavista.com
Excite www.excite.com
HotBot - www.hotbot.com
Nothern Light- www.northernlight.com
Go (Infoseek) www.go.com (infoseek.com)
Fast www.alltheweb.com
Российские поисковые машины:
Яndex - www.yandex.ru (или www.ya.ru) (48% охвата русскоязычных запросов)
Рэмблер - www.rambler.ru
Апорт- www.aport.ru
Метапоисковая система – система, не имеющая своего индекса, способная послать запросы пользователя одновременно нескольким поисковым серверам, затем объединить полученные результаты и представить их пользователю в виде документа со ссылками.
6 Принципы работы метапоисковых систем. Механизмы поиска в интернет. Язык запросов.
При работе метапоисковой системы из полученного от поисковых систем множества документов необходимо выделить наиболее релевантные, то есть соответствующие запросу пользователя.
Простейшие метапоисковые системы реализуют стандартный подход, представленный на рис. 1. В таких системах анализ полученных описаний документов не производится, что может поставить нерелевантные документы, идущие первыми в одной поисковой системе, выше релевантных в другой, чем существенно понизить качество самого поиска.
Рис.1 Стандартная метапоисковая система
При разработке следующего поколения метапоисковых систем были учтены недостатки, присущие стандартным метапоисковым системам. Были созданы системы с возможностью выбора тех поисковых машин, в которых, по мнению пользователя, он с большей вероятностью может найти то, что ему нужно (рис. 2)

Рис. 2. Следующее поколение метапоисковых систем
Кроме этого, такой подход позволяет уменьшить используемые вычислительные ресурсы метапоискового сервера, не перегружая его слишком большим объемом ненужной информации и серьезно сэкономить трафик. Здесь нужно отметить, что в любой системе метапоиска наиболее узким местом в основном является пропускная способность канала передачи данных, так как обработка страниц с результатами поиска, полученными от нескольких десятков поисковых серверов не является слишком трудоемкой операцией, потому что затраты времени на обработку информации на порядки меньше времени прихода страниц, запрошенных у поисковых серверов.
Как пример систем, имеющих подобную организацию, можно назвать Profusion,Ixquick,SavvySearch,MetaPing.
Примером метапоисковой системы является Nigma (Нигма. РФ) - российская интеллектуальнаяметапоисковаясистема.
Программа ускоренного поиска – это программа с возможностями метапоисковой системы, устанавливаемая на локальном компьютере.
Принципиальным отличием метапоисковых систем и программ ускоренного поиска от ИПС является отсутствие своего собственного индекса. Зато они превосходно умеют использовать результаты работы других поисковых систем.
Механизмы поиска
Обобщенная технология поиска состоит из следующих этапов:
Пользователь формулирует запрос
Система проводит поиск документов (или их поисковых образов)
Пользователь получает результат (сведения о документах)
Пользователь совершенствует или реформирует запрос
Организация нового поиска...
Как правило, поисковые машины поддерживают два режима: режим простого поиска и режим расширенного поиска. Рассмотрим обобщенные возможности.
Формирования запроса в режиме простого поиска. Можно просто вводить через пробел одно или несколько слов; поиск слов со всевозможными окончаниями моделируется символом * в конце слова. Многие системы позволяют искать словосочетания или фразу, для этого необходимо ее заключить в кавычки. Возможно обязательное включение или исключение определенных слов.
Основная проблема поиска по примитивно составленному запросу (в виде перечисления ключевых слов) заключается в том, что поисковая машина найдет все страницы, на которых указанные слова встречаются в любой части документа. Как правило, количество найденных страниц будет слишком велико.
Для улучшения качества поиска в режиме простого поиска допустимо использование логических операторов и операторов, позволяющих ограничить область поиска, а также выбор определенной категории документов из представленного списка.
Многие поисковые системы включают в свой язык составления запросов специальные операторы, позволяющие проводить поиск в определенных зонах документа, например, в его заголовке, или искать документ по известной части его адреса.
Режим расширенного или детального запроса в разных системах реализован индивидуально, но чаще всего это бланк, в котором упомянутые операторы и ключевые элементы реализуются простой установкой соответствующих флажков или выбором параметров из списка.
Ниже в качестве примера приведены сведения из раздела помощь поисковой системы Yandex: окно расширенного поиска, язык запросов, искать в найденном.
Искать в найденном Если в результате запроса Яндекс нашел много документов, но по более широкой теме, чем вам хочется, вы можете сократить этот список, уточнив запрос. Еще один вариант - включить флажок в найденном в форме поиска, задать дополнительные ключевые слова, и следующий поиск будет вестись только по тем документам, которые были отобраны в предыдущем поиске.
Памятка по использованию языка запросов
|
Значение |
|
|
"К нам на утренний рассол" |
Слова идут подряд в точной форме |
|
"Прибыл * посол" |
Пропущено слово в цитате |
|
полгорбушки & мосол |
Слова в пределах одного предложения |
|
снаряжайся && добудь |
Слова в пределах одного документа |
|
глухаря | куропатку | кого-нибудь |
Поиск любого из слов |
|
не смогешь << винить |
Неранжирующее "и": выражение после оператора не влияет на позицию документа в выдаче |
|
я должон /2 казнить |
Расстояние в пределах двух слов в любую сторону (то есть между заданными словами может встречаться одно слово) |
|
нешто я ~~ пойму |
Исключение слова пойму из поиска |
|
при моем /+2 уму |
Расстояние в пределах двух слов в прямом порядке |
|
чай ~ лаптем |
Поиск предложения, где слово чай встречается без слова лаптем |
|
щи /(-1 +2) хлебаю |
Расстояние от одного слова в обратном порядке до двух слов в прямом |
|
Соображаю!что!чему |
Слова в точной форме с заданным регистром |
|
получается && (+на | !мне) |
Скобки формируют группы в сложных запросах |
|
Политика |
Словарная форма слова |
|
title:(в стране) |
Поиск по заголовкам документов |
|
url:ptici.narod.ru/ptici/kuropatka.htm |
Поиск по URL |
|
беспременно inurl:vojne |
Поиск с учетом фрагмента URL |
|
Поиск по хосту |
|
|
Поиск по хосту в обратной записи |
|
|
site:http://www.lib.ru/PXESY/FILATOW |
Поиск по всем поддоменам и страницам заданного сайта |
|
Поиск по одному типу файлов |
|
|
Поиск с ограничением по языку |
|
|
Поиск с ограничением по домену |
|
|
Поиск с ограничением по дате |
|
|
государственное дело && /3 улавливаешь нить |
Расстояние в 3 предложения в любую сторону |
|
нешто я ~~ пойму |
Исключение слова пойму из поиска |
Интересной возможностью является поиск документов в сети, ссылающиеся на страницу с указанным вами адресом (URL). Таким образом, можно найти в сети страницы, на которых есть ссылки на ваш Web-сайт. Некоторые системы позволят ограничить область поиска внутри указанного домена.
В качестве дополнительных специальных операторов можно выделить:
Операторы поиска документов с определенным графическим файлом;
Операторы ограничения по дате искомых страниц;
Операторы близости между словами;
Операторы учета словоформы;
Операторы сортировки результатов (по релевантности, свежести, старости).
Следует заметить, что, к великому сожалению, на сегодняшний день не существует стандарта на количество и синтаксис поддерживаемых операторов для различных поисковых систем. Попытки разработать стандарт на синтаксис поддерживаемых операторов предпринимаются, поэтому есть надежда на то, что разработчики поисковых систем позаботятся об удобстве пользователей. На данном этапе развития средств поиска, пользователь, обращаясь к определенной поисковой системе, непременно должен в первую очередь ознакомиться с ее правилами составления запросов. Как правило, на домашней странице будет обязательно присутствовать ссылка Помощь (Help), по которой вы перейдете к справочной информации.
Различные поисковые системы описывают разное количество источников информации в Интернет. Поэтому нельзя ограничиваться поиском только в одной из указанных поисковых системах.
Рассмотрим способы представления результатов поиска в поисковых машинах.
Чаще всего количество найденных документов превышает несколько десятков, а в отдельных случаях может достигать сотен тысяч! Поэтому в качестве формы выдачи составляется список документов по 5-10-15 единиц на странице с возможностью перехода к следующей порции внизу страницы. Обязательно указывается заголовок и URL(адрес) найденного документа, иногда система указывает в процентах степень релевантности документа.
В описании документа чаще всего содержится несколько первых предложений или выдержки из текста документа с выделением ключевых слов. Как правило, указана дата обновления (проверки) документа, его размер в килобайтах, некоторые системы определяют язык документа и его кодировку (для русскоязычных документов).
Что можно делать с полученными результатами? Если название и описание документа соответствует вашим требованиям, можно немедленно перейти к его первоисточнику по ссылке. Это удобнее делать в новом окне, чтобы иметь возможность далее анализировать результаты выдачи. Многие поисковые системы позволяют проводить поиск в найденных документах, причем вы можете уточнить ваш запрос введением дополнительных терминов.
Если интеллектуальность системы высока, вам могут предложить услугу поиска похожих документов. Для этого вы выбираете особо понравившийся документ и указываете его системе в качестве образца для подражания.
Однако, автоматизация определение похожести – весьма нетривиальная задача, и зачастую эта функция работает неадекватно вашим надеждам. Некоторые поисковики позволяют провести пересортировку результатов. Для экономии вашего времени можно сохранить результаты поиска в виде файла на локальном диске для последующего изучения в автономном режиме.











